Publications
2026
-
 LikeBench: Evaluating Subjective Likability in LLMs for PersonalizationMd Awsafur Rahman, Adam Gabryś, Daniel Kang, and 3 more authorsPreprint, 2026
LikeBench: Evaluating Subjective Likability in LLMs for PersonalizationMd Awsafur Rahman, Adam Gabryś, Daniel Kang, and 3 more authorsPreprint, 2026LikeBench is a novel benchmark for evaluating subjective likability in large language models for personalization applications.
@article{rahman2025likebench, title = {LikeBench: Evaluating Subjective Likability in LLMs for Personalization}, author = {Rahman, Md Awsafur and Gabryś, Adam and Kang, Daniel and Tan, Tianjian and Sun, Jiayi and Chandramouli, Ashwin}, journal = {Preprint}, year = {2026}, } -
 Click2Graph: Interactive Panoptic Video Scene Graphs from a Sidsddngle ClickRaphael Ruschel, Hardik Prajapati, Md Awsafur Rahman, and 1 more authorPreprint, 2026
Click2Graph: Interactive Panoptic Video Scene Graphs from a Sidsddngle ClickRaphael Ruschel, Hardik Prajapati, Md Awsafur Rahman, and 1 more authorPreprint, 2026Interactive panoptic video scene graph generation from a single user click, enabling efficient video understanding and analysis.
@article{ruschel2025click2graph, title = {Click2Graph: Interactive Panoptic Video Scene Graphs from a Sidsddngle Click}, author = {Ruschel, Raphael and Prajapati, Hardik and Rahman, Md Awsafur and Manjunath, BS}, journal = {Preprint}, year = {2026}, } -
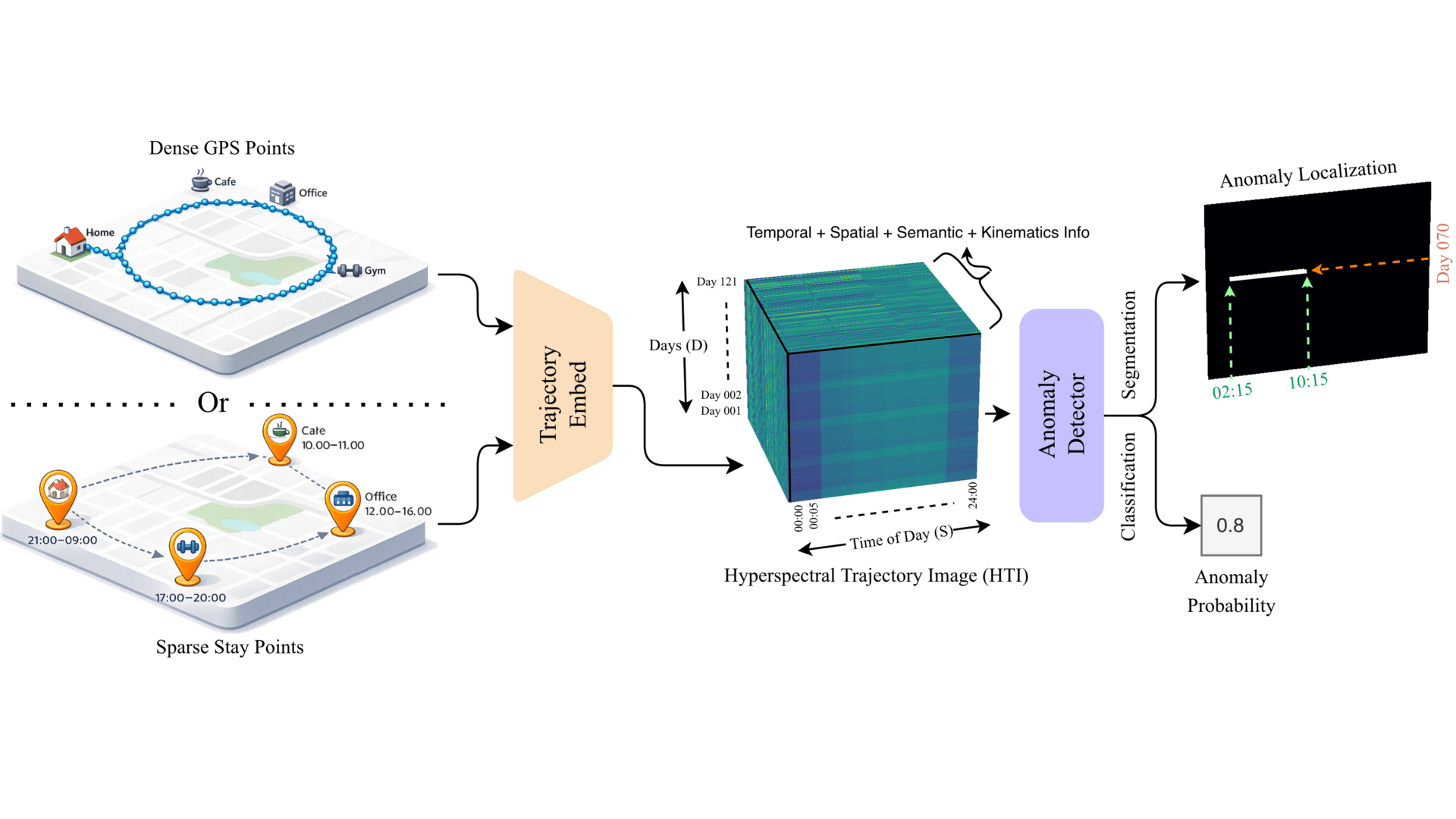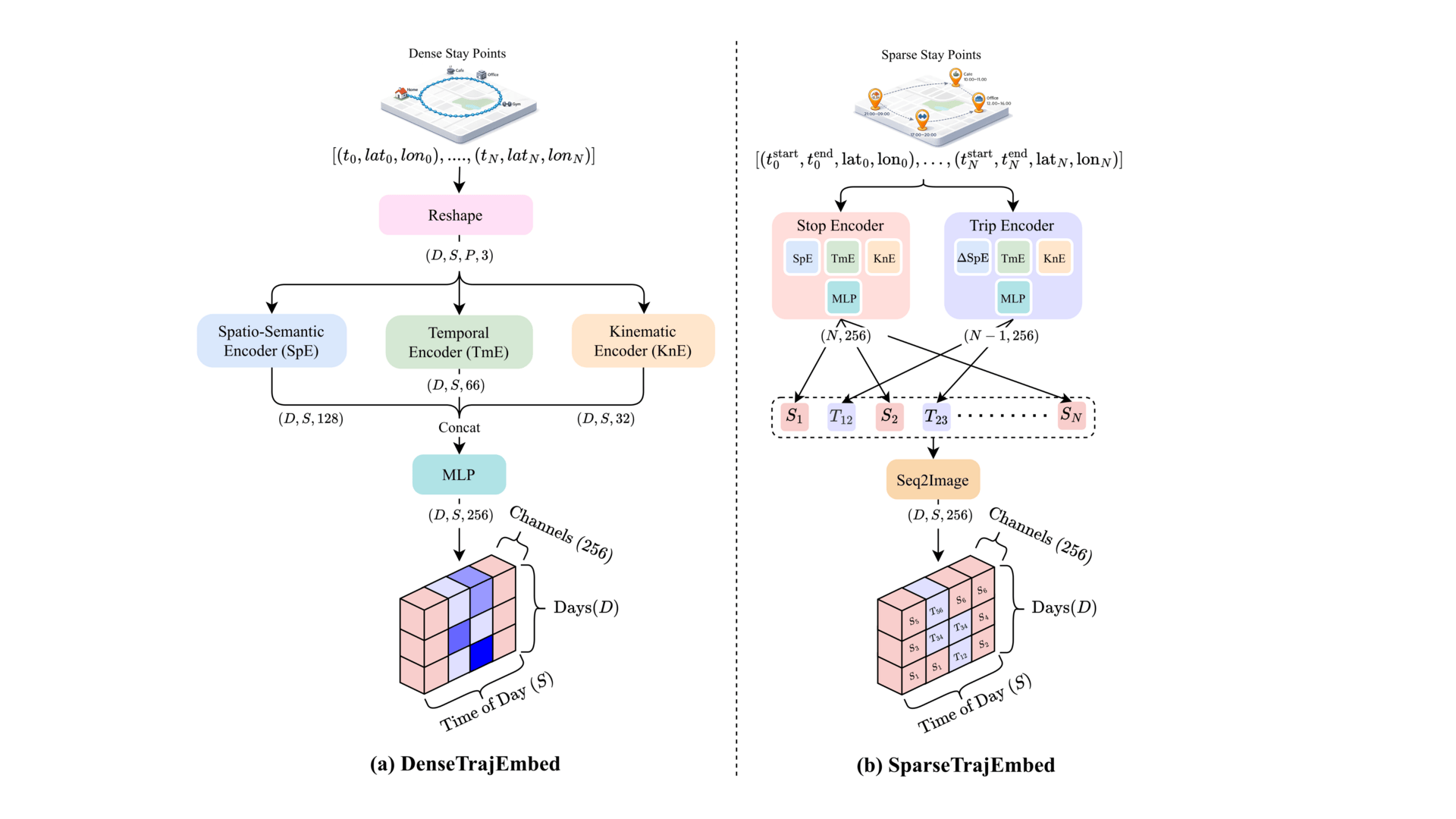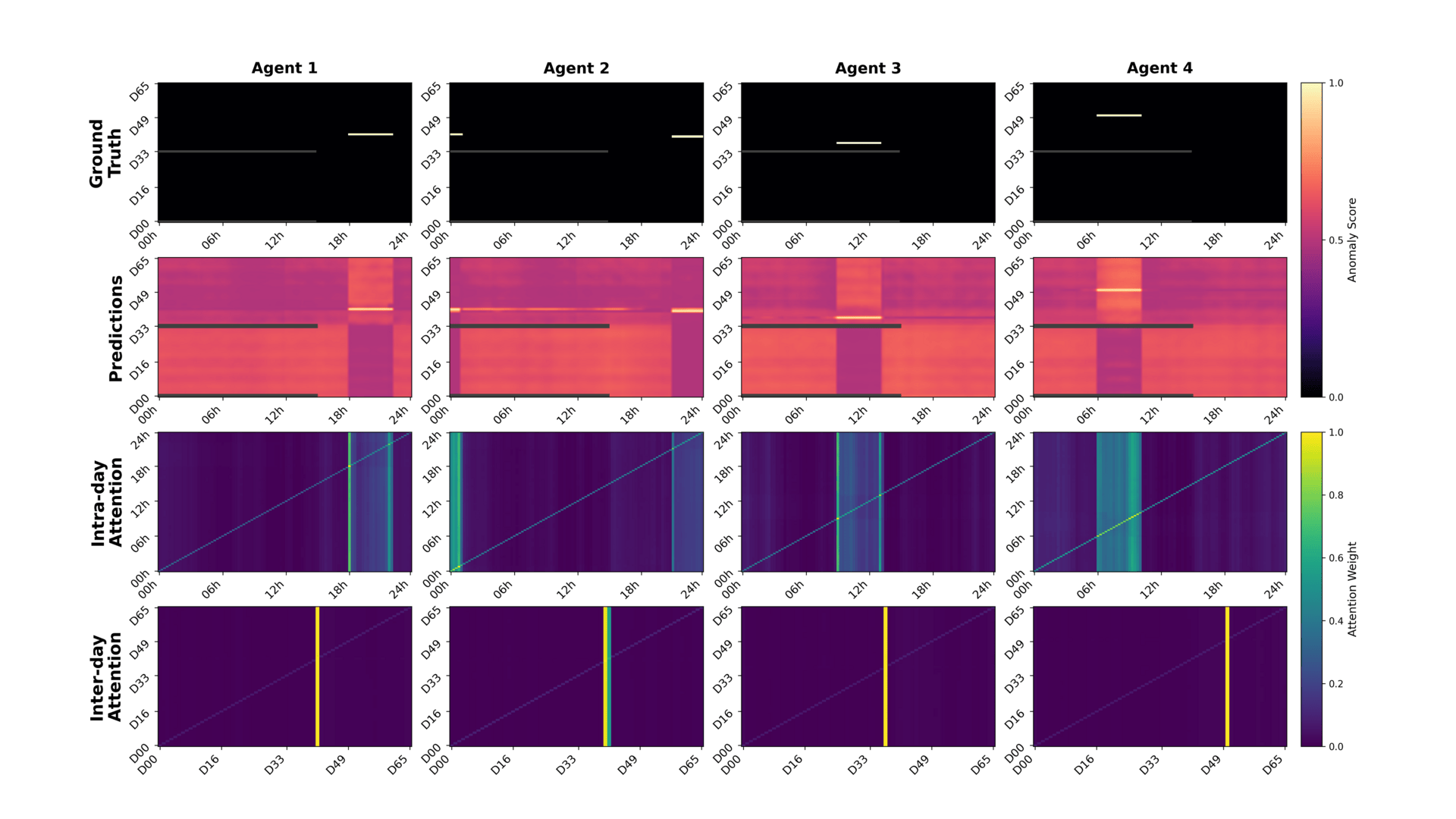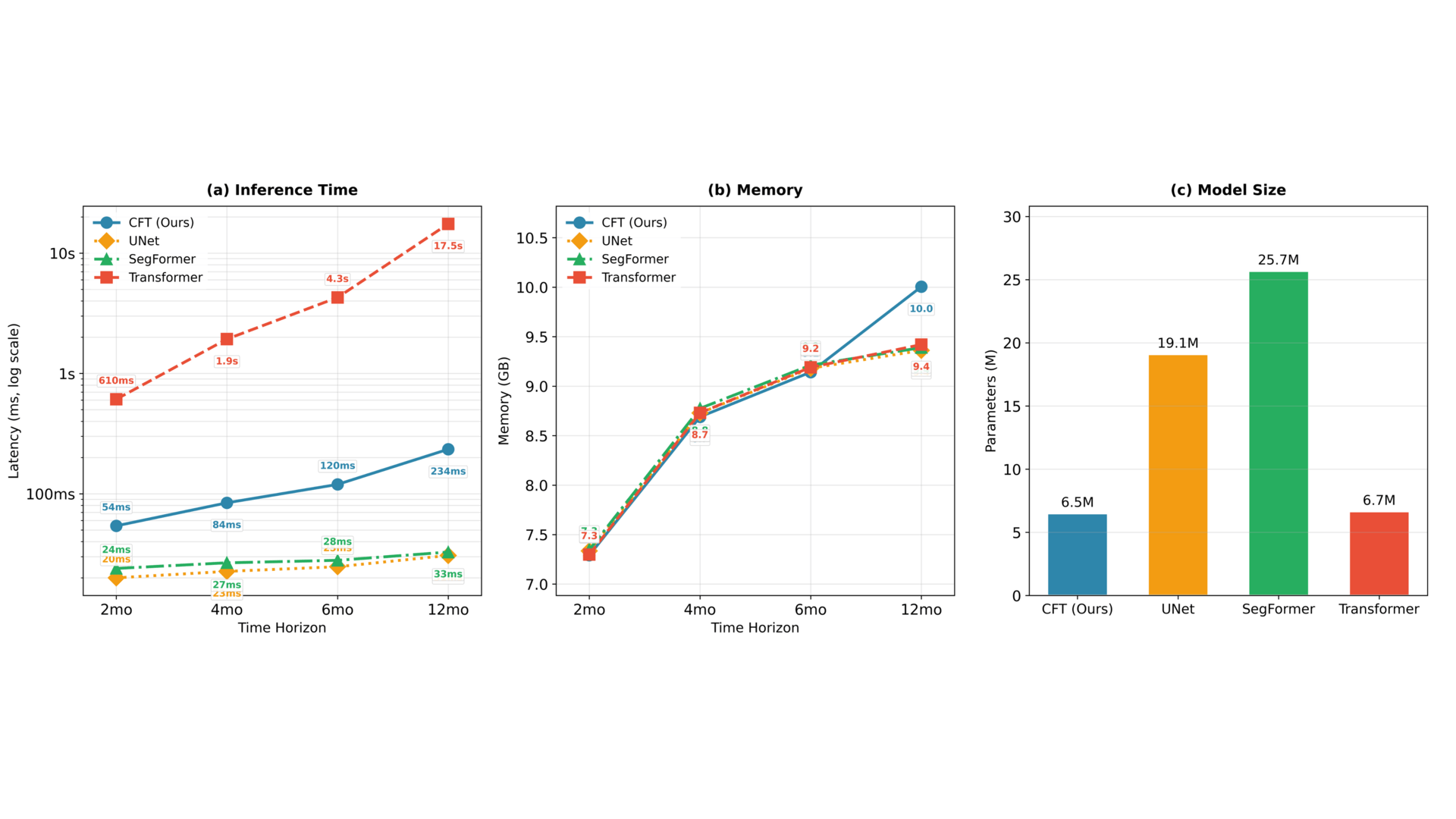 Hyperspectral Trajectory Image for Multi-Month Trajectory Anomaly DetectionMd Awsafur Rahman, Chandrakanth Gudavalli, Hardik Prajapati, and 1 more authorPreprint, 2026
Hyperspectral Trajectory Image for Multi-Month Trajectory Anomaly DetectionMd Awsafur Rahman, Chandrakanth Gudavalli, Hardik Prajapati, and 1 more authorPreprint, 2026Trajectory anomaly detection underpins applications from fraud detection to urban mobility analysis. Dense GPS methods preserve fine-grained evidence such as abnormal speeds and short-duration events, but their quadratic cost makes multi-month analysis intractable; consequently, no existing approach detects anomalies over multi-month dense GPS trajectories. The field instead relies on scalable sparse stay-point methods that discard this evidence, forcing separate architectures for each regime and preventing knowledge transfer. We argue this bottleneck is unnecessary: human trajectories, dense or sparse, share a natural two-dimensional cyclic structure along within-day and across-day axes. We therefore propose TITAnD (Trajectory Image Transformer for Anomaly Detection), which reformulates trajectory anomaly detection as a vision problem by representing trajectories as a Hyperspectral Trajectory Image (HTI): a day x time-of-day grid whose channels encode spatial, semantic, temporal, and kinematic information from either modality, unifying both under a single representation. Under this formulation, agent-level detection reduces to image classification and temporal localization to semantic segmentation. To model this representation, we introduce the Cyclic Factorized Transformer (CFT), which factorizes attention along the two temporal axes, encoding the cyclic inductive bias of human routines, while reducing attention cost by orders of magnitude and enabling dense multi-month anomaly detection for the first time. Empirically, TITAnD achieves the best AUC-PR across sparse and dense benchmarks, surpassing vision models like UNet while being 11-75x faster than the Transformer with comparable memory, demonstrating that vision reformulation and structure-aware modeling are jointly essential. Code will be made public soon.
@article{rahman2026titand, title = {Hyperspectral Trajectory Image for Multi-Month Trajectory Anomaly Detection}, author = {Rahman, Md Awsafur and Gudavalli, Chandrakanth and Prajapati, Hardik and Manjunath, B. S.}, journal = {Preprint}, year = {2026}, }



2025
-
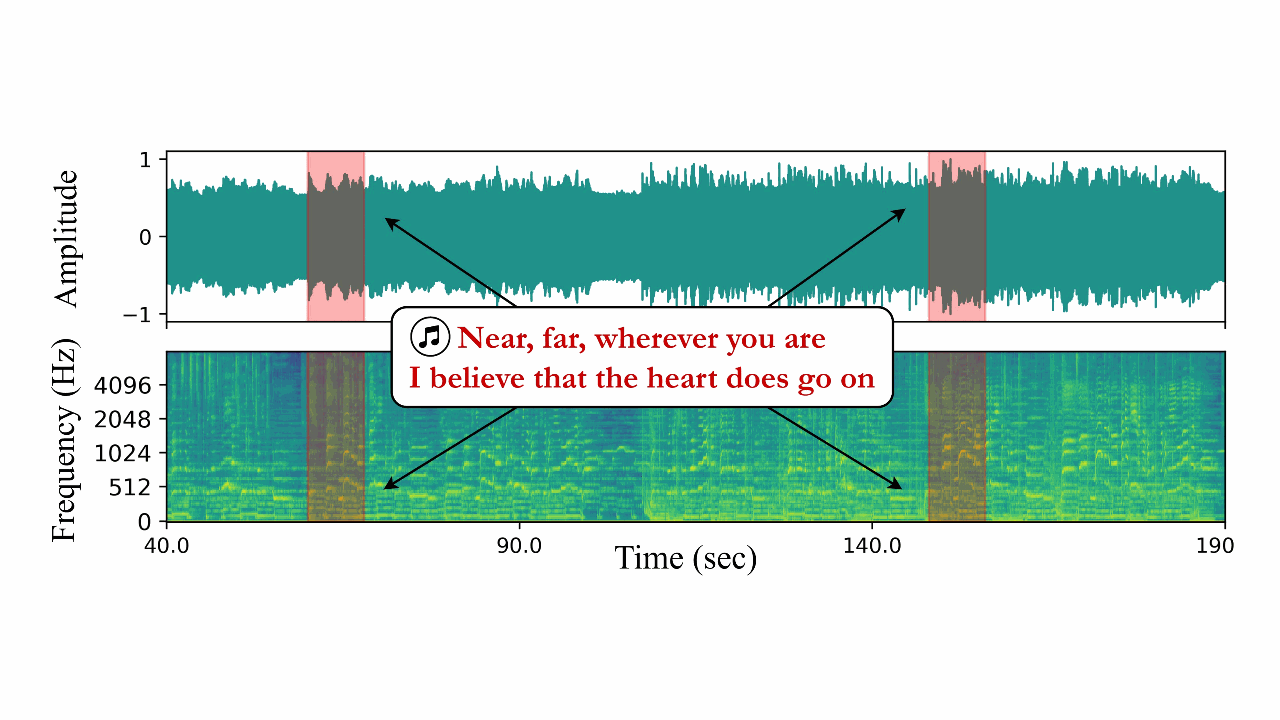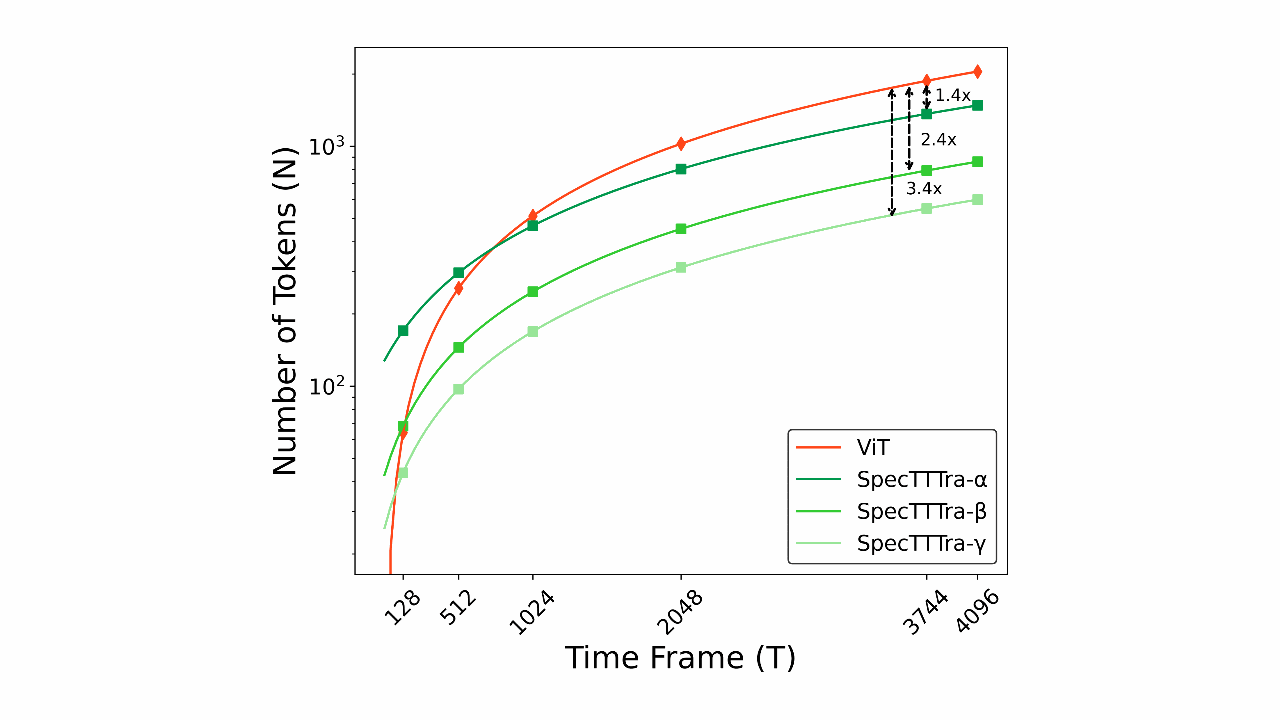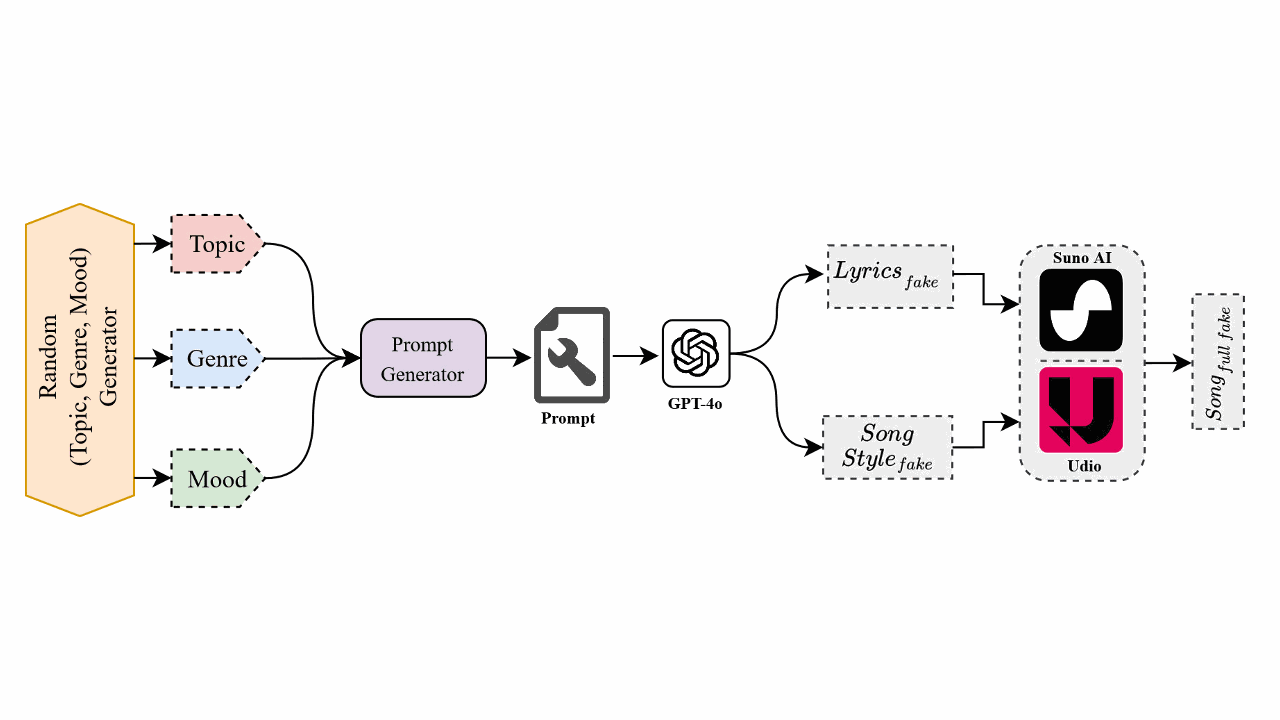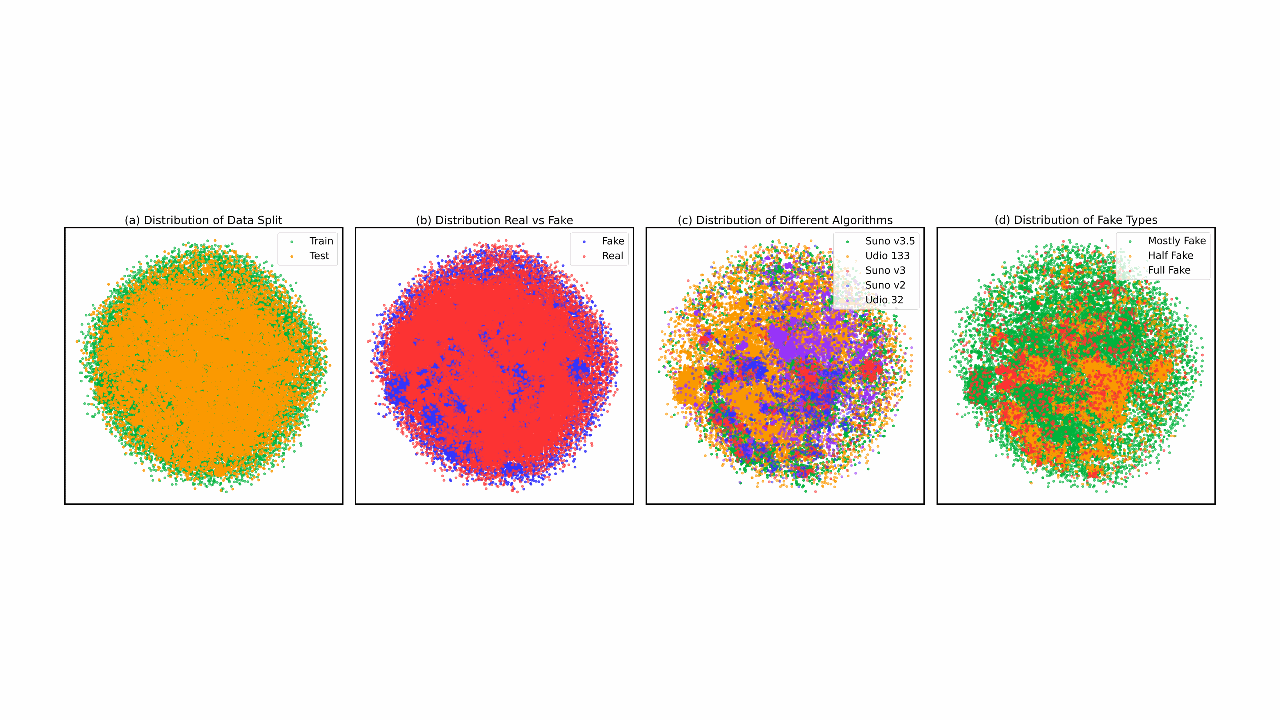 SONICS: Synthetic Or Not - Identifying Counterfeit SongsMd Awsafur Rahman, Zaber Ibn Abdul Hakim, Najibul Haque Sarker, and 2 more authorsInternational Conference on Learning Representations (ICLR), 2025
SONICS: Synthetic Or Not - Identifying Counterfeit SongsMd Awsafur Rahman, Zaber Ibn Abdul Hakim, Najibul Haque Sarker, and 2 more authorsInternational Conference on Learning Representations (ICLR), 2025The recent surge in AI-generated songs presents exciting possibilities and challenges. These innovations necessitate the ability to distinguish between human-composed and synthetic songs to safeguard artistic integrity and protect human musical artistry. Existing research and datasets in fake song detection only focus on singing voice deepfake detection (SVDD), where the vocals are AI-generated but the instrumental music is sourced from real songs. However, these approaches are inadequate for detecting contemporary end-to-end artificial songs where all components (vocals, music, lyrics, and style) could be AI-generated. Additionally, existing datasets lack music-lyrics diversity, long-duration songs, and open-access fake songs. To address these gaps, we introduce SONICS, a novel dataset for end-to-end Synthetic Song Detection (SSD), comprising over 97k songs (4,751 hours) with over 49k synthetic songs from popular platforms like Suno and Udio. Furthermore, we highlight the importance of modeling long-range temporal dependencies in songs for effective authenticity detection, an aspect entirely overlooked in existing methods. To utilize long-range patterns, we introduce SpecTTTra, a novel architecture that significantly improves time and memory efficiency over conventional CNN and Transformer-based models. For long songs, our top-performing variant outperforms ViT by 8% in F1 score, is 38% faster, and uses 26% less memory, while also surpassing ConvNeXt with a 1% F1 score gain, 20% speed boost, and 67% memory reduction.
@article{rahman2024sonics, title = {SONICS: Synthetic Or Not - Identifying Counterfeit Songs}, author = {Rahman, Md Awsafur and Hakim, Zaber Ibn Abdul and Sarker, Najibul Haque and Paul, Bishmoy and Fattah, Shaikh Anowarul}, journal = {International Conference on Learning Representations (ICLR)}, doi = {10.48550/arXiv.2408.14080}, year = {2025}, dataset = {https://huggingface.co/datasets/awsaf49/sonics}, } - Temporally Consistent Dynamic Scene Graphs: An End-to-End Approach for Action Tracklet GenerationRaphael Ruschel, Md Awsafur Rahman, Hardik Prajapati, and 2 more authorsPreprint, 2025
Understanding video content is pivotal for advancing real-world applications like activity recognition, autonomous systems, and human-computer interaction. While scene graphs are adept at capturing spatial relationships between objects in individual frames, extending these representations to capture dynamic interactions across video sequences remains a significant challenge. To address this, we present TCDSG, Temporally Consistent Dynamic Scene Graphs, an innovative end-to-end framework that detects, tracks, and links subject-object relationships across time, generating action tracklets, temporally consistent sequences of entities and their interactions. Our approach leverages a novel bipartite matching mechanism, enhanced by adaptive decoder queries and feedback loops, ensuring temporal coherence and robust tracking over extended sequences. This method not only establishes a new benchmark by achieving over 60% improvement in temporal recall@k on the Action Genome, OpenPVSG, and MEVA datasets but also pioneers the augmentation of MEVA with persistent object ID annotations for comprehensive tracklet generation. By seamlessly integrating spatial and temporal dynamics, our work sets a new standard in multi-frame video analysis, opening new avenues for high-impact applications in surveillance, autonomous navigation, and beyond.
@article{ruschel2024temporally, title = {Temporally Consistent Dynamic Scene Graphs: An End-to-End Approach for Action Tracklet Generation}, author = {Ruschel, Raphael and Rahman, Md Awsafur and Prajapati, Hardik and You, Suya and Manjuanth, BS}, journal = {Preprint}, year = {2025}, }

2024
-
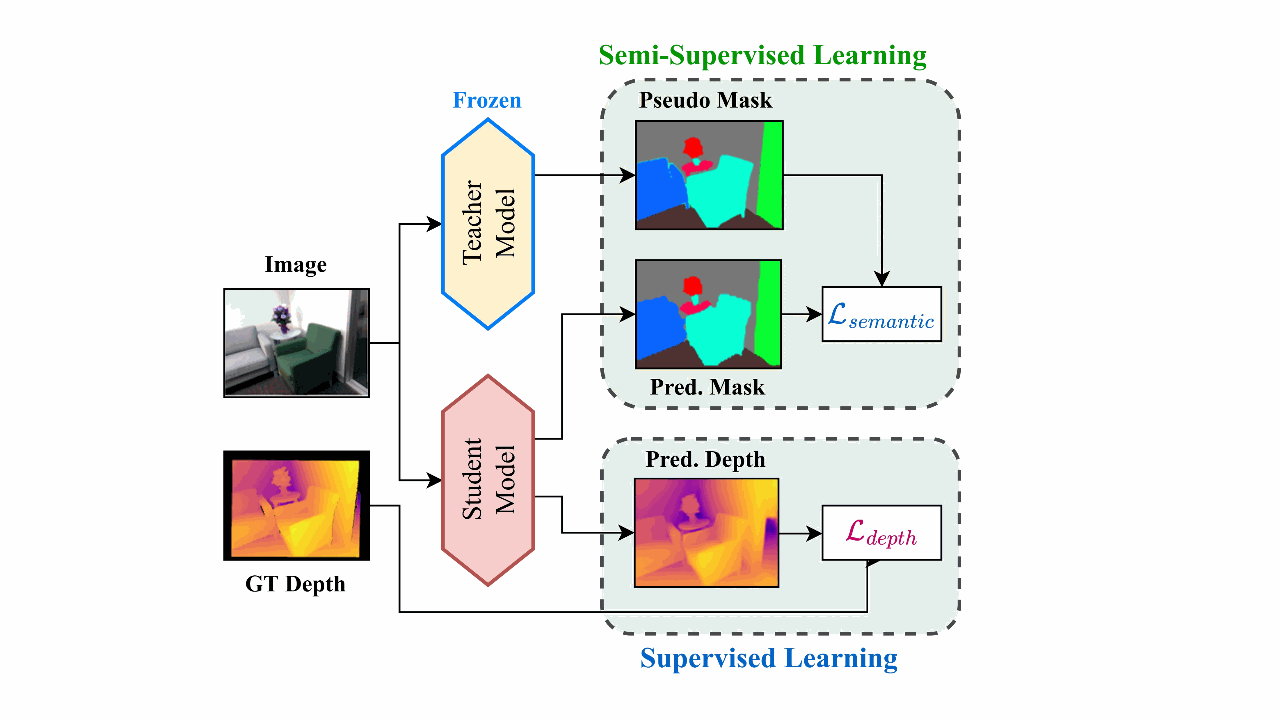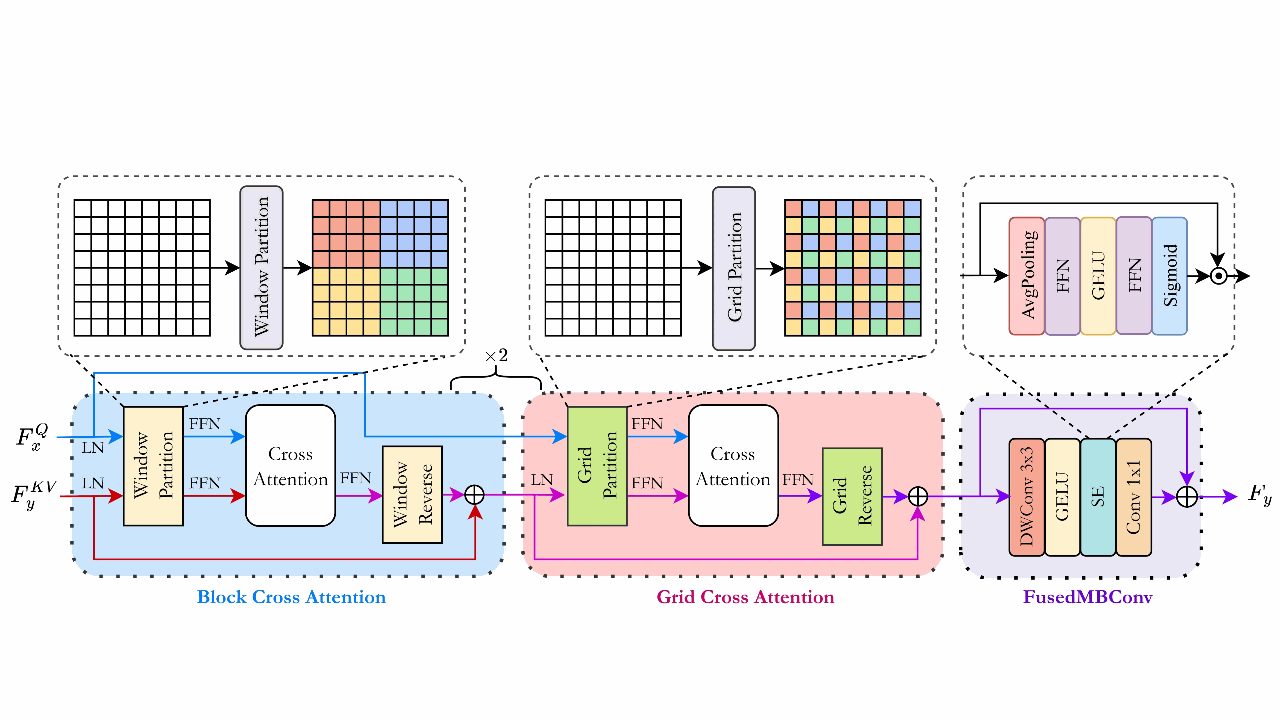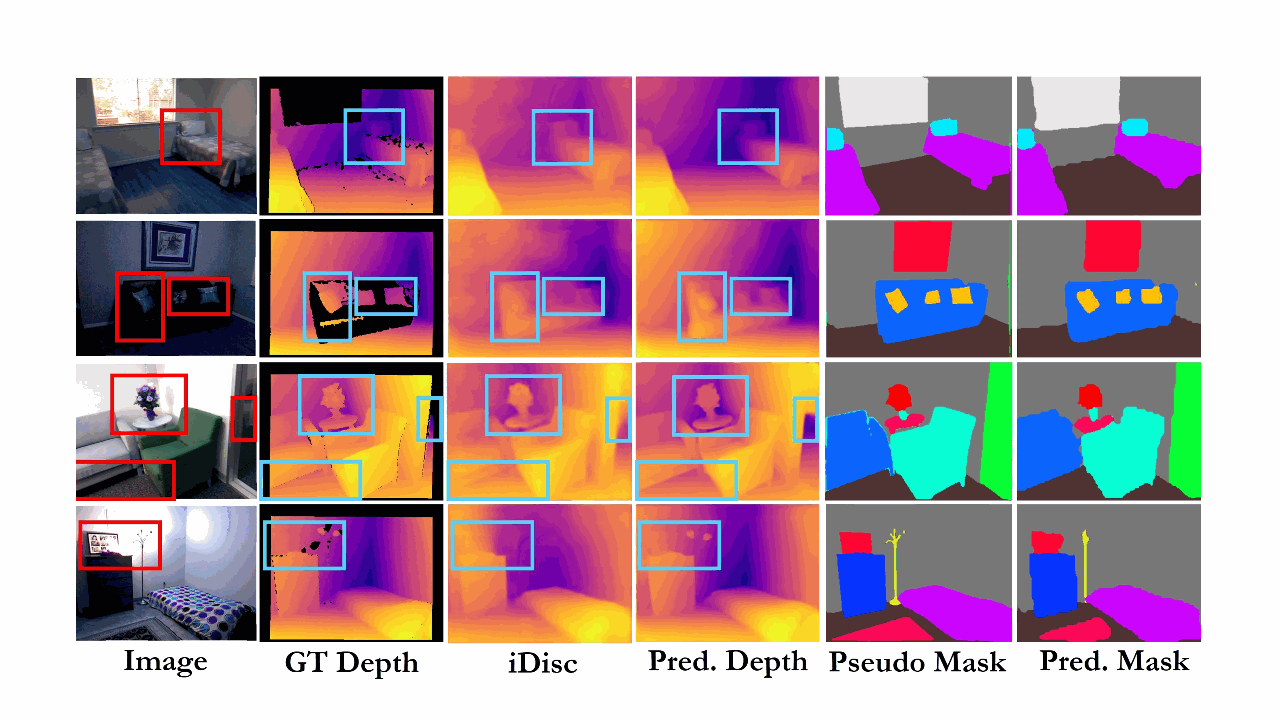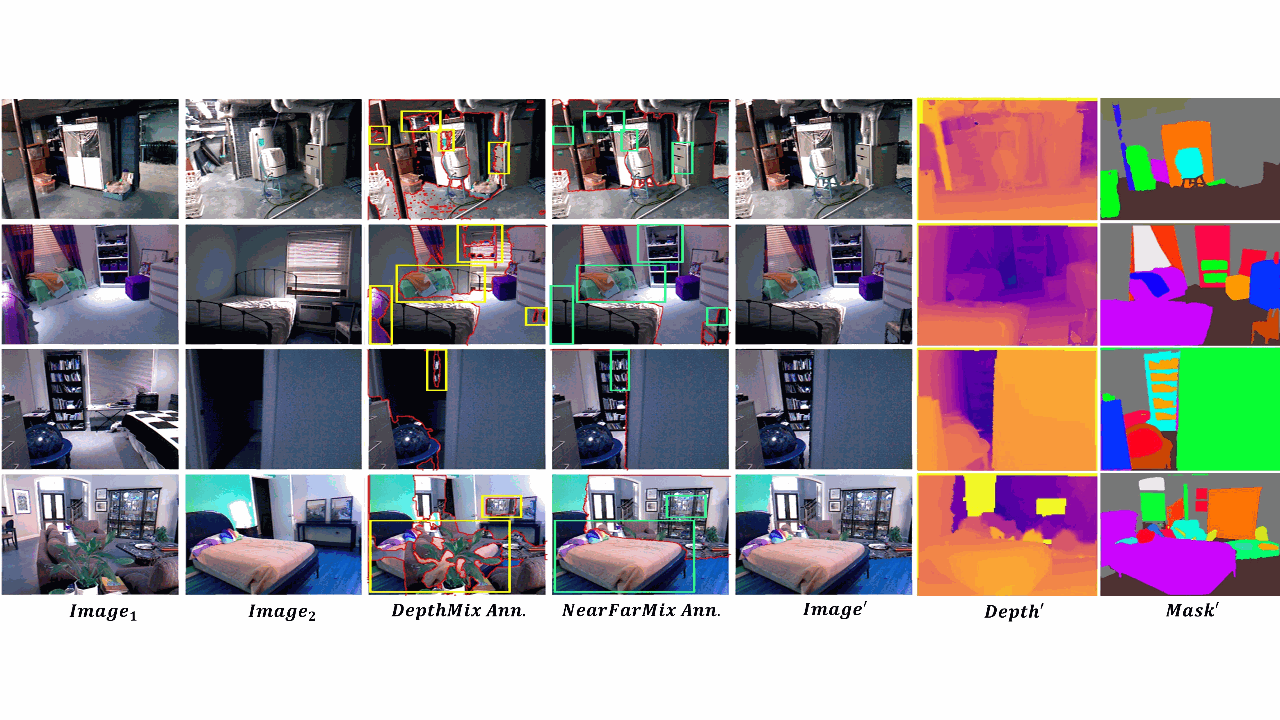 Semi-Supervised Semantic Depth Estimation using Symbiotic Transformer and NearFarMix AugmentationMd Awsafur Rahman, and Shaikh Anowarul FattahWACV, 2024
Semi-Supervised Semantic Depth Estimation using Symbiotic Transformer and NearFarMix AugmentationMd Awsafur Rahman, and Shaikh Anowarul FattahWACV, 2024In computer vision, depth estimation is crucial for domains like robotics, autonomous vehicles, augmented reality, and virtual reality. Integrating semantics with depth enhances scene understanding through reciprocal information sharing. However, the scarcity of semantic information in datasets poses challenges. Existing convolutional approaches with limited local receptive fields hinder the full utilization of the symbiotic potential between depth and semantics. This paper introduces a dataset-invariant semi-supervised strategy to address the scarcity of semantic information. It proposes the Depth Semantics Symbiosis module, leveraging the Symbiotic Transformer for achieving comprehensive mutual awareness by information exchange within both local and global contexts. Additionally, a novel augmentation, NearFarMix is introduced to combat overfitting and compensate both depth-semantic tasks by strategically merging regions from two images, generating diverse and structurally consistent samples with enhanced control. Extensive experiments on NYU-Depth-V2 and KITTI datasets demonstrate the superiority of our proposed techniques in indoor and outdoor environments.
@article{rahman2023sytra, title = {Semi-Supervised Semantic Depth Estimation using Symbiotic Transformer and NearFarMix Augmentation}, author = {Rahman, Md Awsafur and Fattah, Shaikh Anowarul}, journal = {WACV}, year = {2024}, organization = {IEEE/CVF}, doi = {10.48550/arXiv.2308.14400}, youtube = {-5YidVH9wIA}, } -
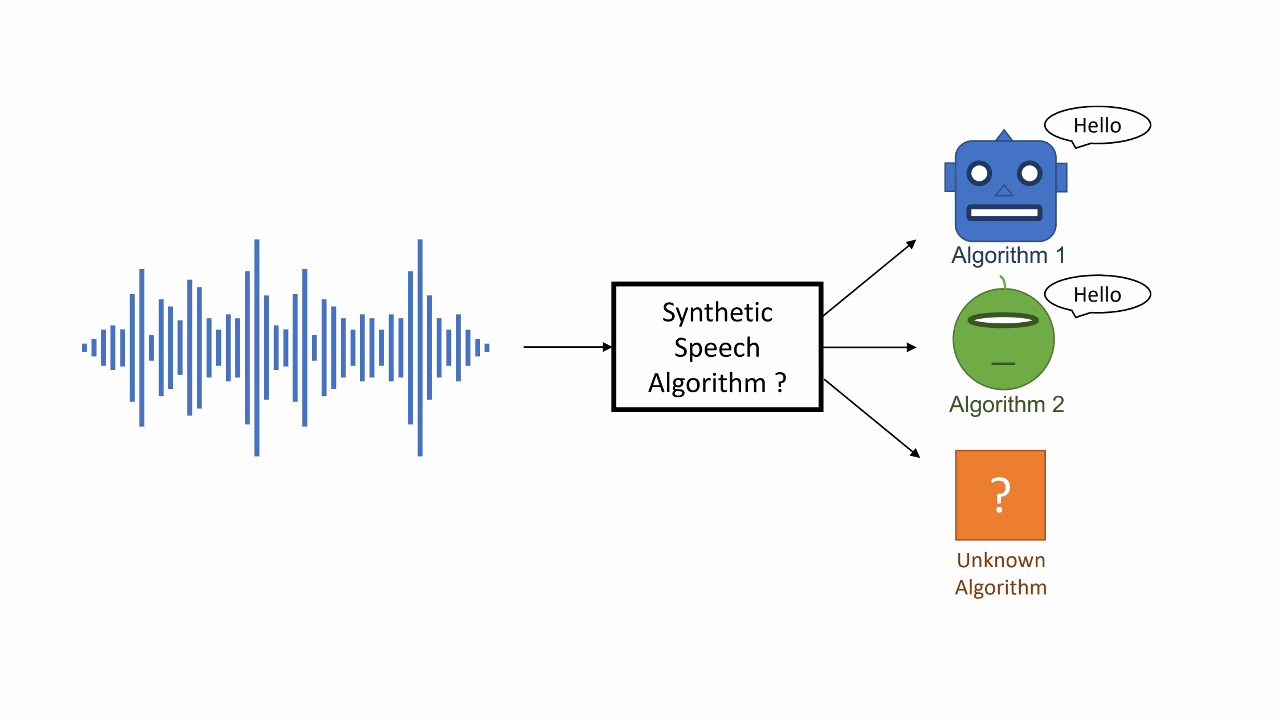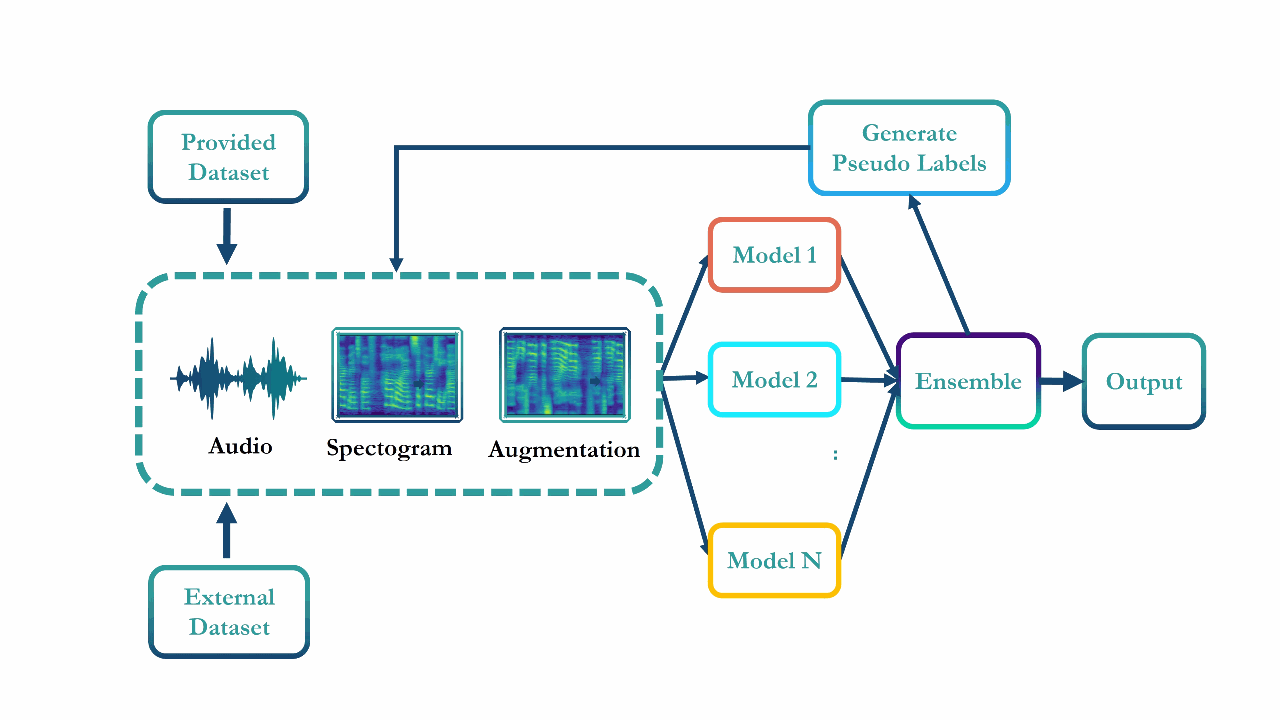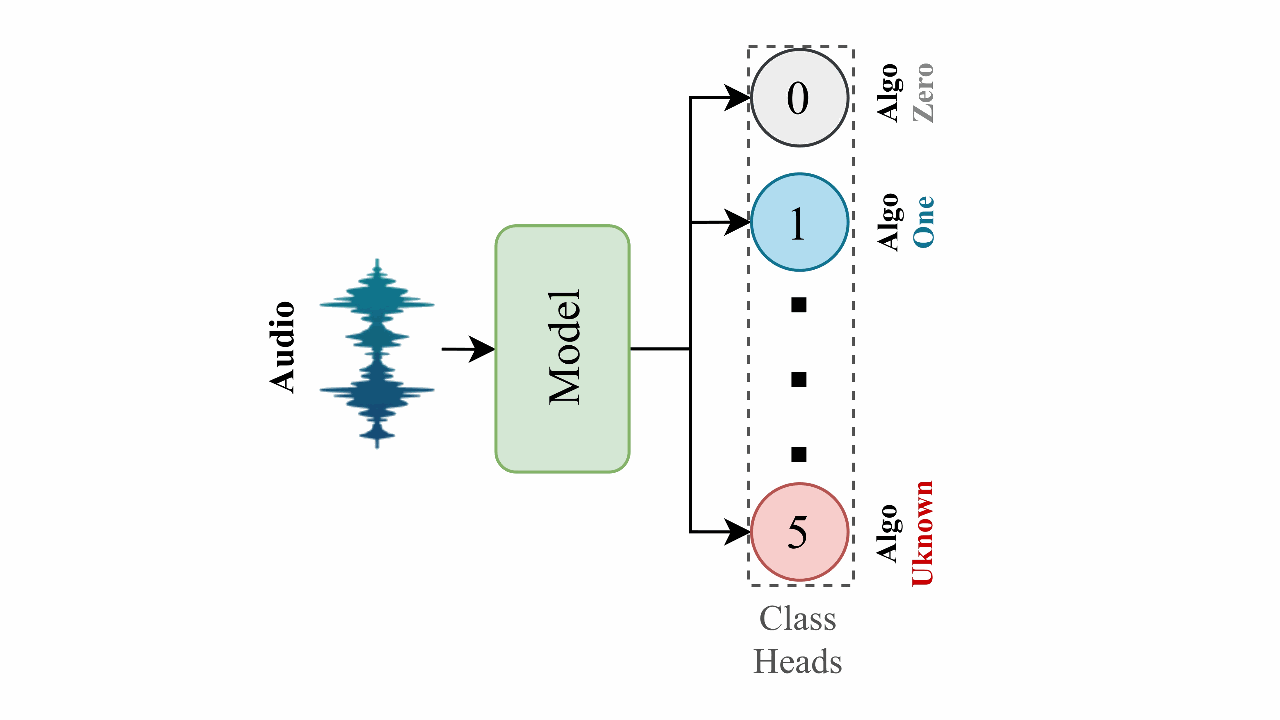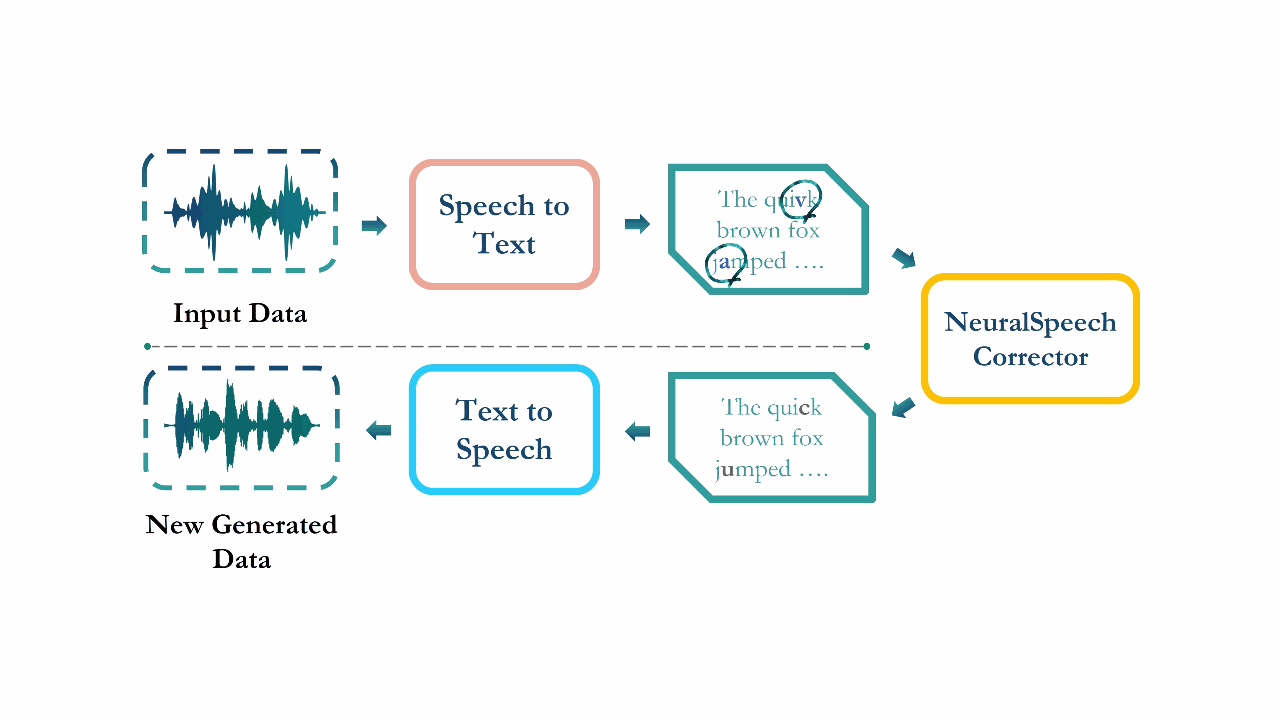 Syn-Att: Synthetic Speech Attribution via Semi-Supervised Unknown Multi-Class Ensemble of CNNsMd Awsafur Rahman, Bishmoy Paul, Najibul Haque Sarker, and 3 more authors2024
Syn-Att: Synthetic Speech Attribution via Semi-Supervised Unknown Multi-Class Ensemble of CNNsMd Awsafur Rahman, Bishmoy Paul, Najibul Haque Sarker, and 3 more authors2024With the huge technological advances introduced by deep learning in audio & speech processing, many novel synthetic speech techniques achieved incredible realistic results. As these methods generate realistic fake human voices, they can be used in malicious acts such as people imitation, fake news, spreading, spoofing, media manipulations, etc. Hence, the ability to detect synthetic or natural speech has become an urgent necessity. Moreover, being able to tell which algorithm has been used to generate a synthetic speech track can be of preeminent importance to track down the culprit. In this paper, a novel strategy is proposed to attribute a synthetic speech track to the generator that is used to synthesize it. The proposed detector transforms the audio into log-mel spectrogram, extracts features using CNN, and classifies it between five known and unknown algorithms, utilizing semi-supervision and ensemble to improve its robustness and generalizability significantly. The proposed detector is validated on two evaluation datasets consisting of a total of 18,000 weakly perturbed (Eval 1) & 10,000 strongly perturbed (Eval 2) synthetic speeches. The proposed method outperforms other top teams in accuracy by 12-13% on Eval 2 and 1-2% on Eval 1, in the IEEE SP Cup challenge at ICASSP 2022.
@article{rahman2023syn, title = {Syn-Att: Synthetic Speech Attribution via Semi-Supervised Unknown Multi-Class Ensemble of CNNs}, author = {Rahman, Md Awsafur and Paul, Bishmoy and Sarker, Najibul Haque and Hakim, Zaber Ibn Abdul and Fattah, Shaikh Anowarul and Saquib, Mohammad}, journal = {}, year = {2024}, dataset = {https://www.kaggle.com/datasets/awsaf49/sp22-synthetic-dataset}, doi = {10.48550/arXiv.2309.08146}, }


2023
-
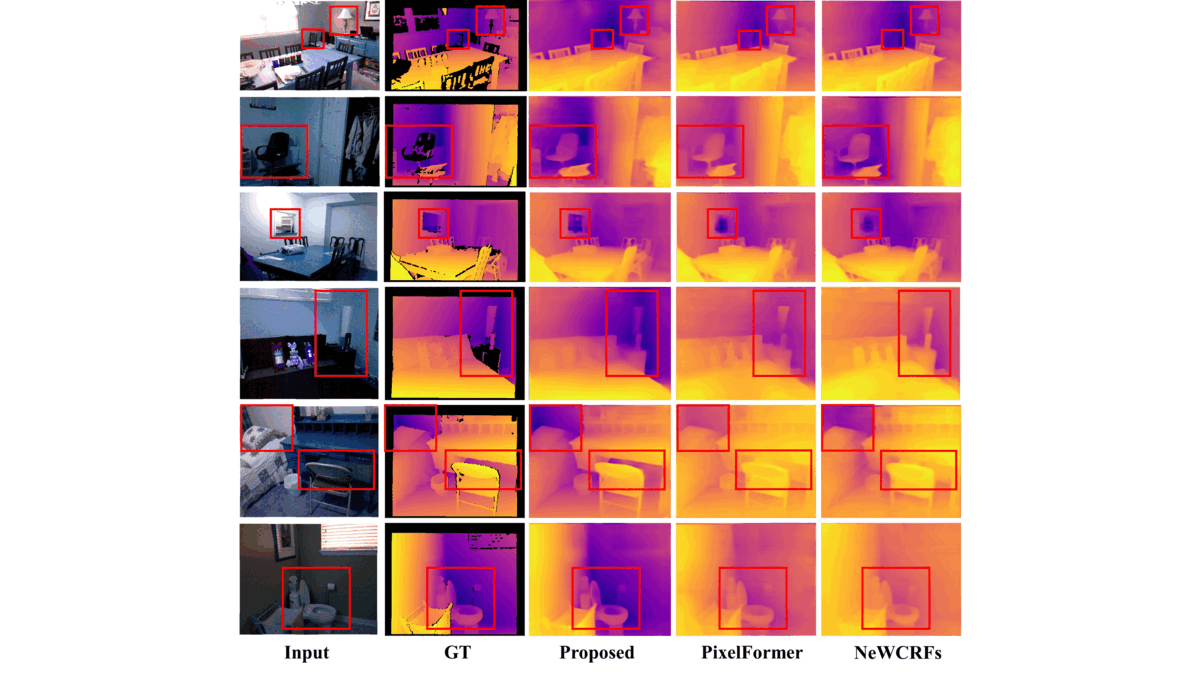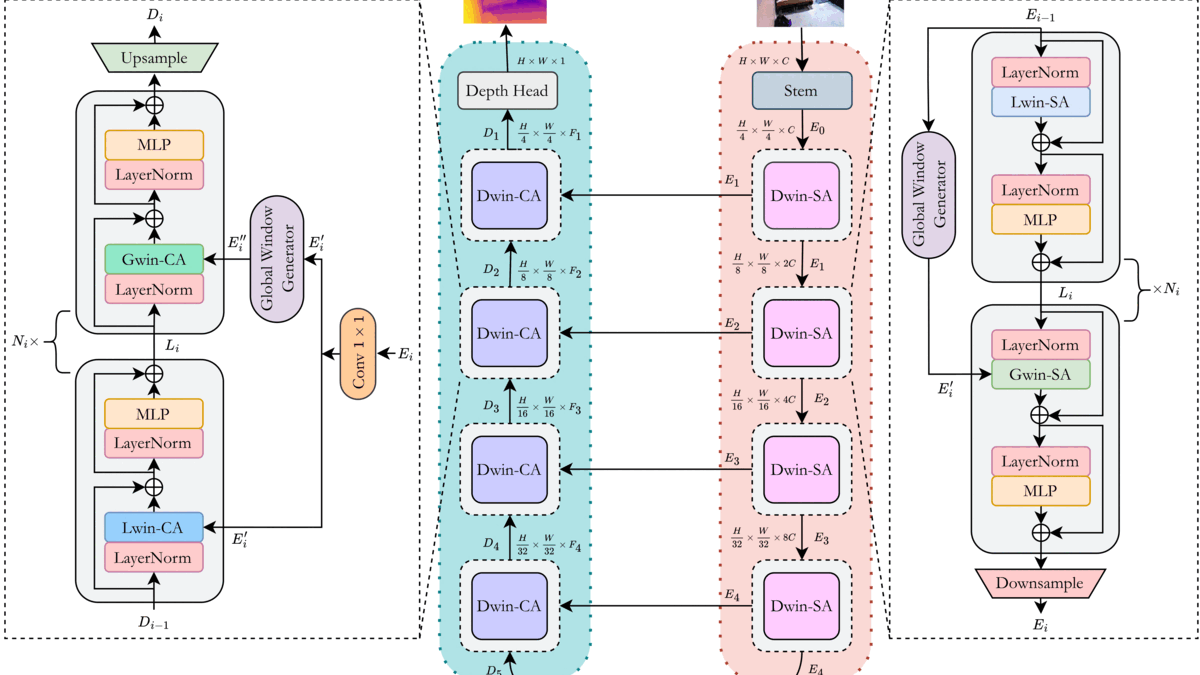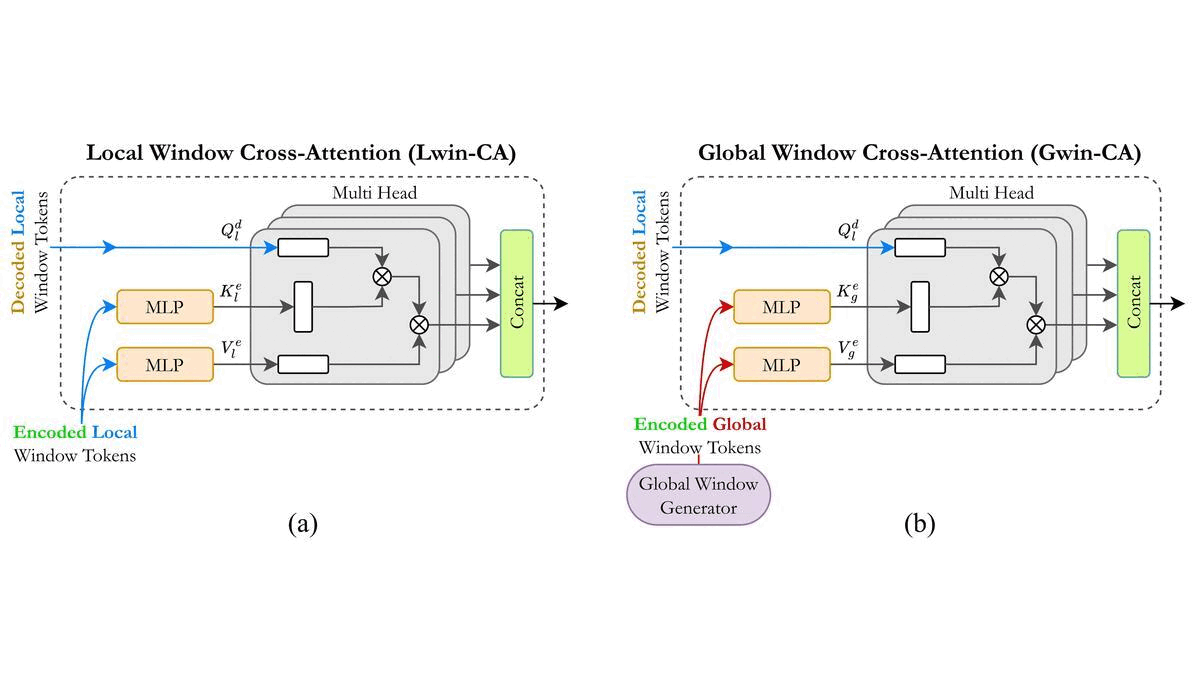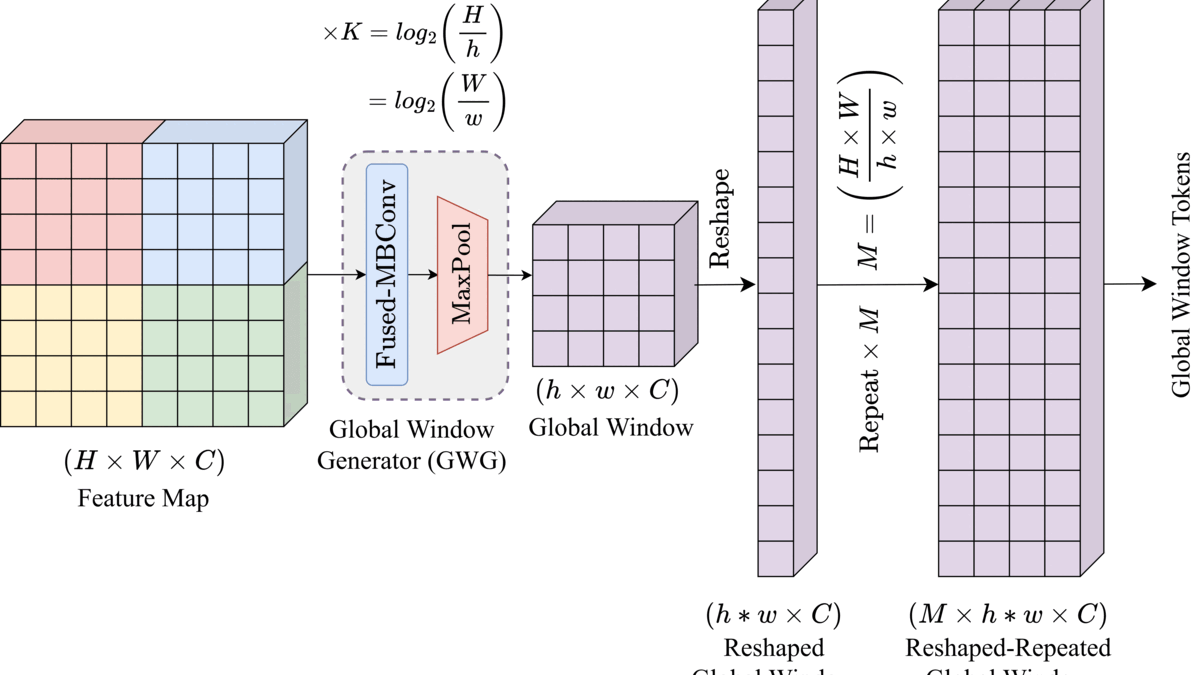 DwinFormer: Dual Window Transformers for End-to-End Monocular Depth EstimationMd Awsafur Rahman, and Shaikh Anowarul FattahIEEE Sensors Journal, 2023
DwinFormer: Dual Window Transformers for End-to-End Monocular Depth EstimationMd Awsafur Rahman, and Shaikh Anowarul FattahIEEE Sensors Journal, 2023Depth estimation from a single image is of paramount importance in the realm of computer vision, with a multitude of applications. Conventional methods suffer from the trade-off between consistency and fine-grained details due to the local-receptive field limiting their practicality. This lack of long-range dependency inherently comes from the convolutional neural network part of the architecture. In this paper, a dual window transformer-based network, namely DwinFormer, is proposed, which utilizes both local and global features for end-to-end monocular depth estimation. The DwinFormer consists of dual window self-attention and cross-attention transformers, Dwin-SAT and Dwin-CAT, respectively. The Dwin-SAT seamlessly extracts intricate, locally aware features while concurrently capturing global context. It harnesses the power of local and global window attention to adeptly capture both short-range and long-range dependencies, obviating the need for complex and computationally expensive operations, such as attention masking or window shifting. Moreover, Dwin-SAT introduces inductive biases which provide desirable properties, such as translational equvariance and less dependence on large-scale data. Furthermore, conventional decoding methods often rely on skip connections which may result in semantic discrepancies and a lack of global context when fusing encoder and decoder features. In contrast, the Dwin-CAT employs both local and global window cross-attention to seamlessly fuse encoder and decoder features with both fine-grained local and contextually aware global information, effectively amending semantic gap. Empirical evidence obtained through extensive experimentation on the NYU-Depth-V2 and KITTI datasets demonstrates the superiority of the proposed method, consistently outperforming existing approaches across both indoor and outdoor environments.
@article{rahman2023dwinformer, title = {DwinFormer: Dual Window Transformers for End-to-End Monocular Depth Estimation}, author = {Rahman, Md Awsafur and Fattah, Shaikh Anowarul}, journal = {IEEE Sensors Journal}, year = {2023}, doi = {10.1109/JSEN.2023.3299782}, url = {https://scholar.google.com/citations?view_op=view_citation&hl=en&user=zrxJCYIAAAAJ&citation_for_view=zrxJCYIAAAAJ:IjCSPb-OGe4C}, } -
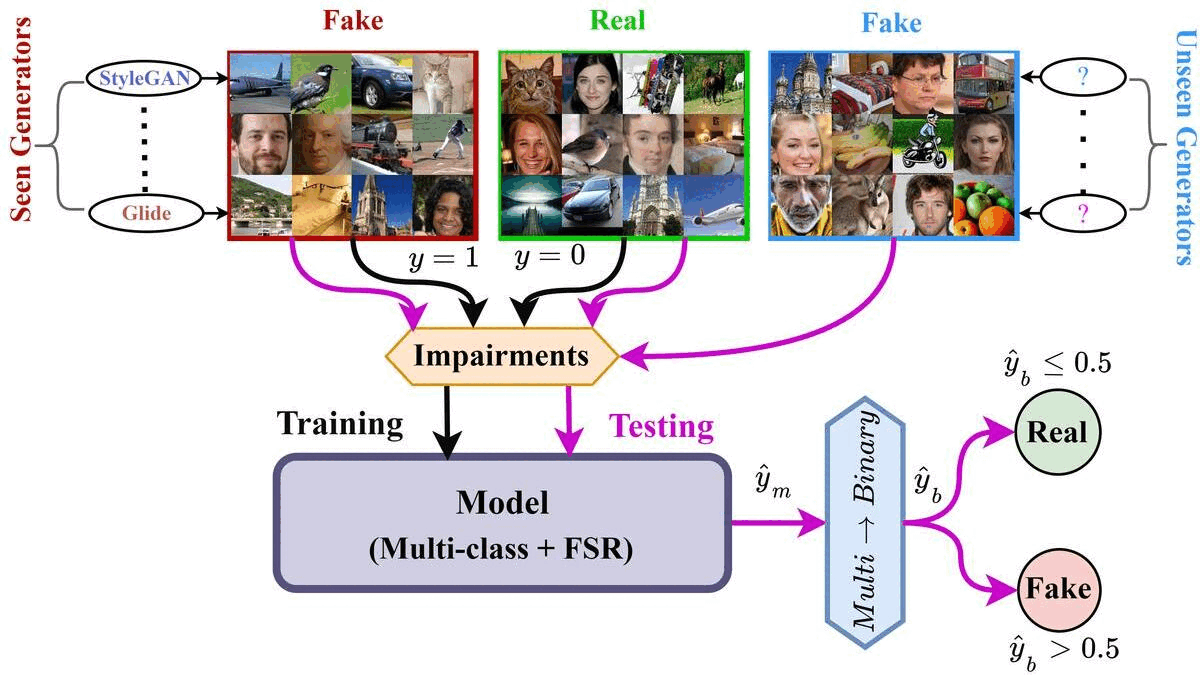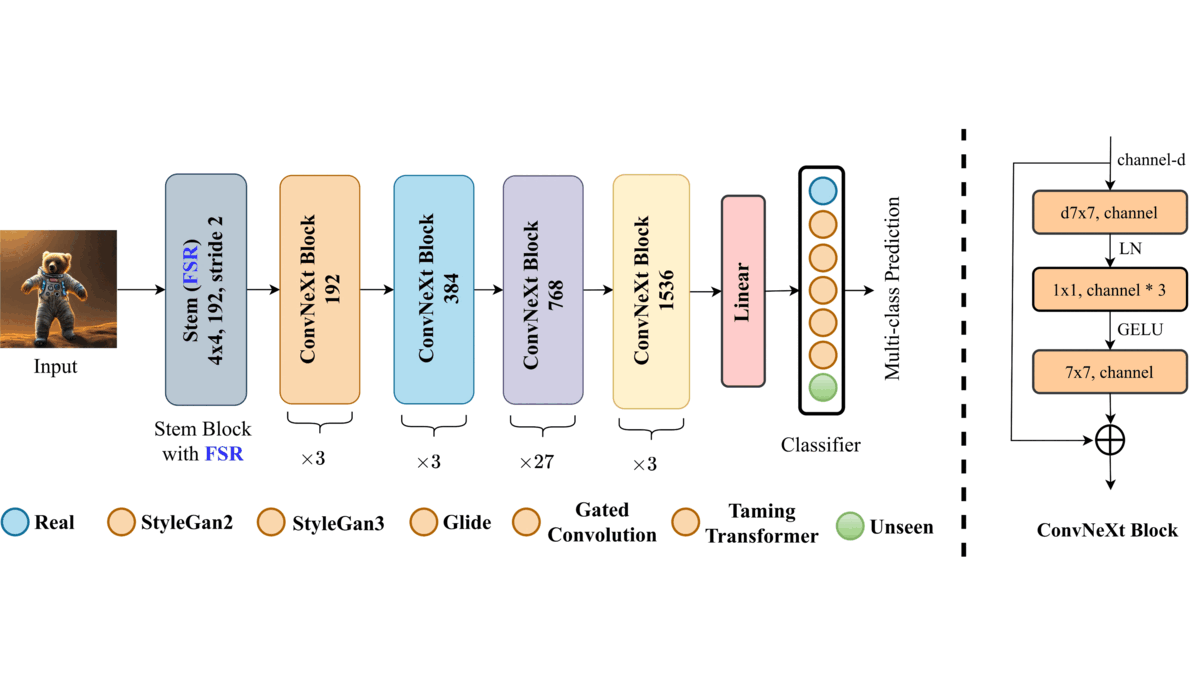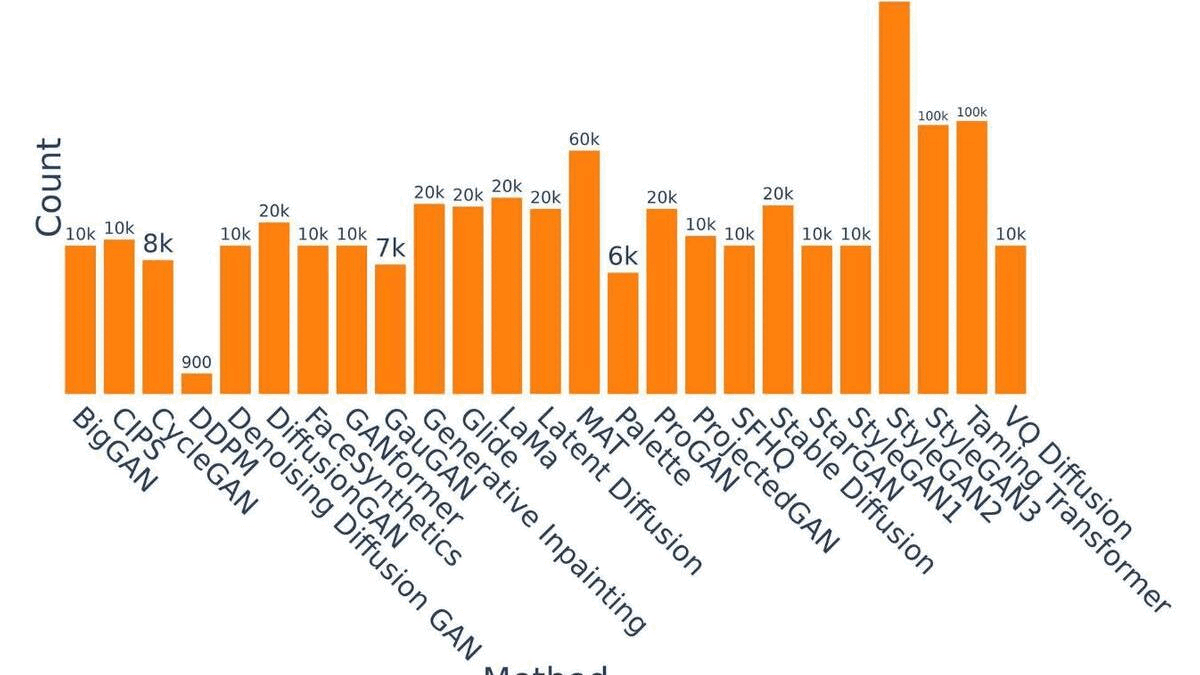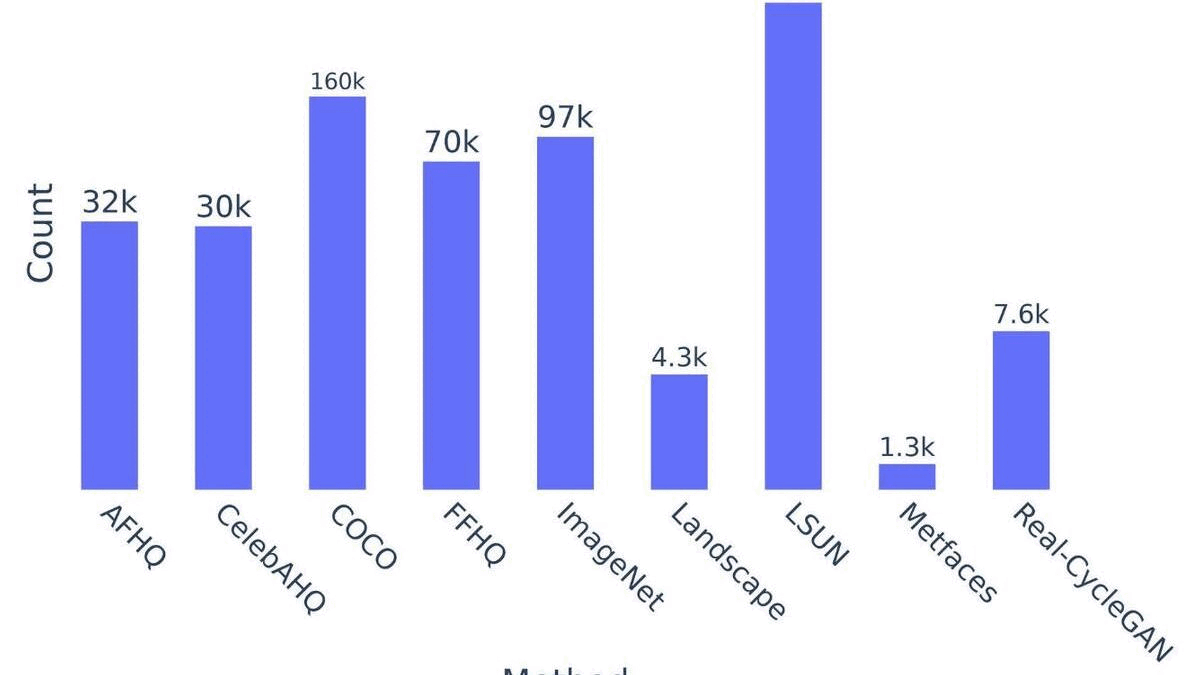 ArtiFact: A Large-Scale Dataset with Artificial and Factual Images for Generalizable and Robust Synthetic Image DetectionMd Awsafur Rahman, Bishmoy Paul, Najibul Haque Sarker, and 2 more authorsICIP, 2023
ArtiFact: A Large-Scale Dataset with Artificial and Factual Images for Generalizable and Robust Synthetic Image DetectionMd Awsafur Rahman, Bishmoy Paul, Najibul Haque Sarker, and 2 more authorsICIP, 2023Synthetic image generation has opened up new opportunities but has also created threats in regard to privacy, authenticity, and security. Detecting fake images is of paramount importance to prevent illegal activities, and previous research has shown that generative models leave unique patterns in their synthetic images that can be exploited to detect them. However, the fundamental problem of generalization remains, as even state-of-the-art detectors encounter difficulty when facing generators never seen during training. To assess the generalizability and robustness of synthetic image detectors in the face of real-world impairments, this paper presents a large-scale dataset named ArtiFact, comprising diverse generators, object categories, and real-world challenges. Moreover, the proposed multi-class classification scheme, combined with a filter stride reduction strategy addresses social platform impairments and effectively detects synthetic images from both seen and unseen generators. The proposed solution outperforms other teams by 8.34% on Test 1, 1.26% on Test 2, and 15.08% on Test 3 in the IEEE VIP CUP at ICIP 2022.
@article{rahman2023artifact, title = {ArtiFact: A Large-Scale Dataset with Artificial and Factual Images for Generalizable and Robust Synthetic Image Detection}, author = {Rahman, Md Awsafur and Paul, Bishmoy and Sarker, Najibul Haque and Hakim, Zaber Ibn Abdul and Fattah, Shaikh Anowarul}, journal = {ICIP}, year = {2023}, doi = {10.1109/ICIP49359.2023.10222083}, url = {https://scholar.google.com/citations?view_op=view_citation&hl=en&user=zrxJCYIAAAAJ&citation_for_view=zrxJCYIAAAAJ:qjMakFHDy7sC}, dataset = {https://www.kaggle.com/datasets/awsaf49/artifact-dataset}, youtube = {hGXufeubNME}, } -
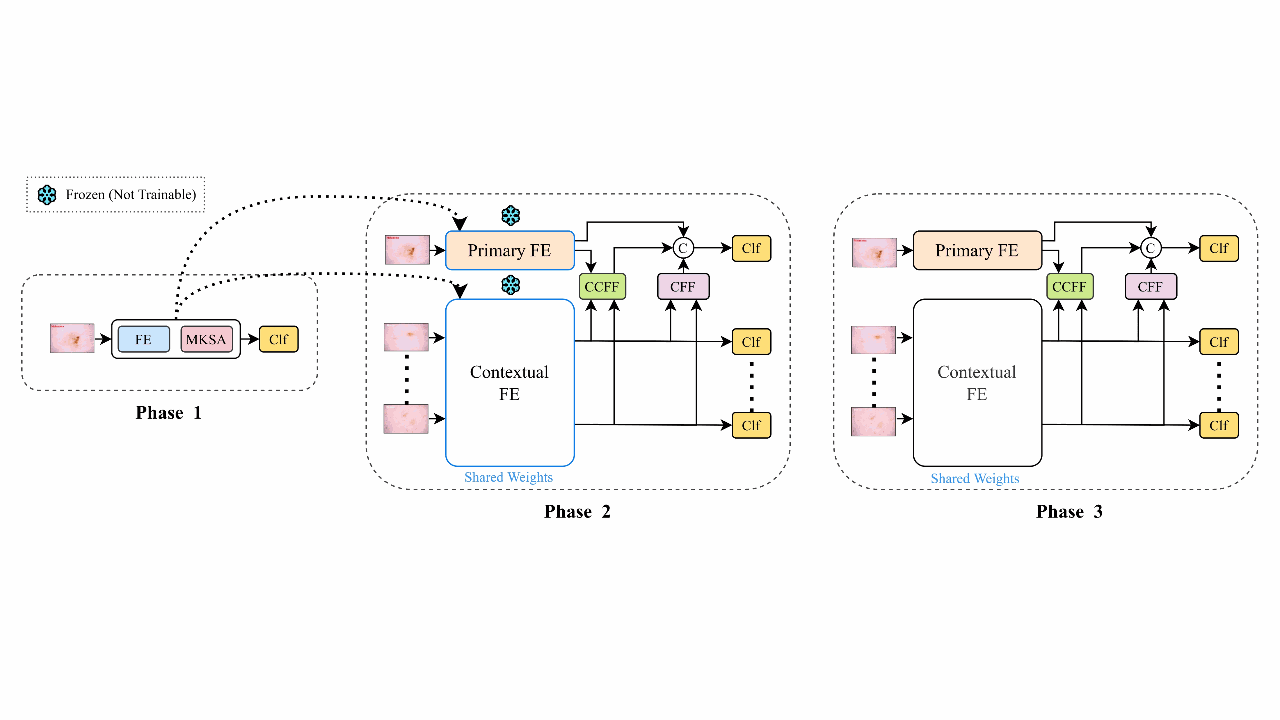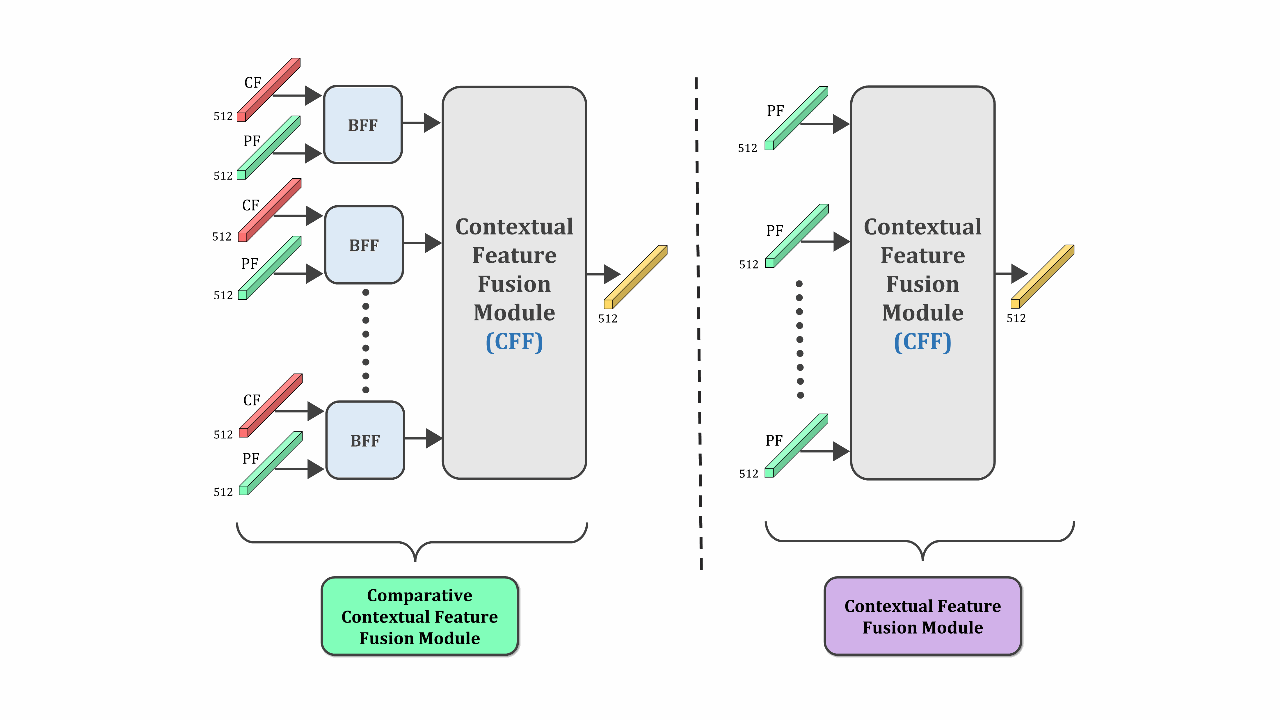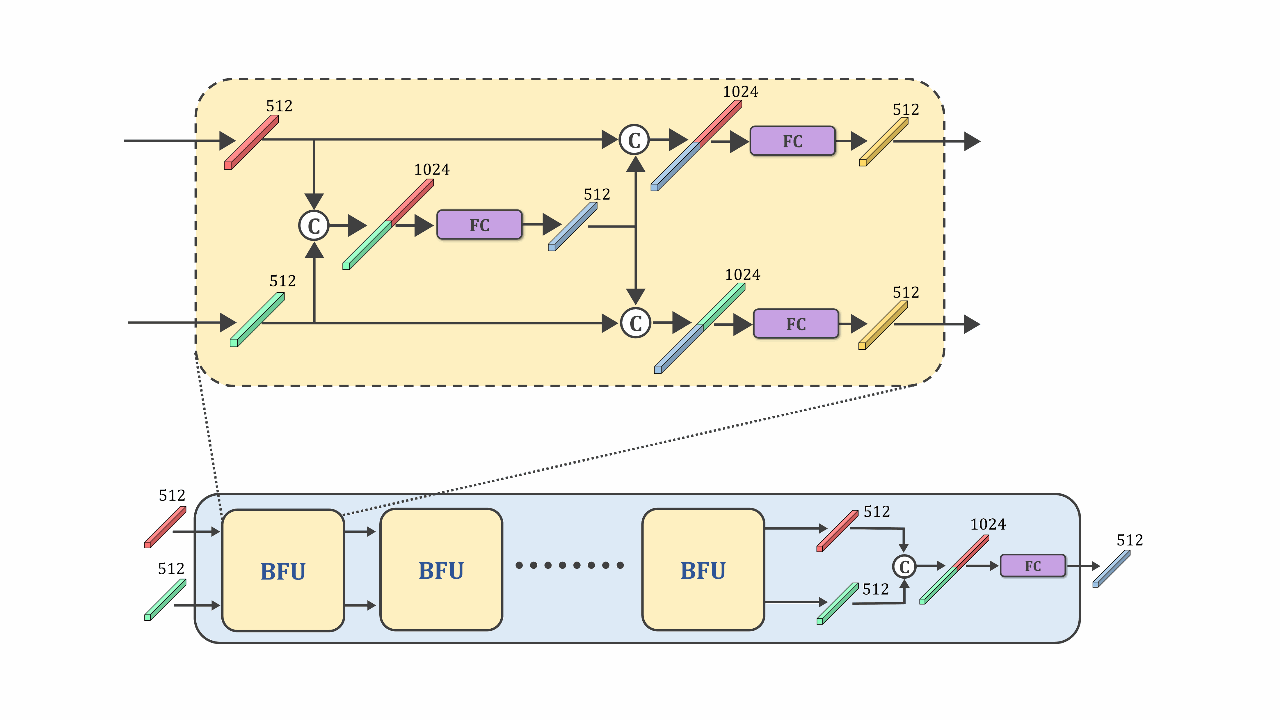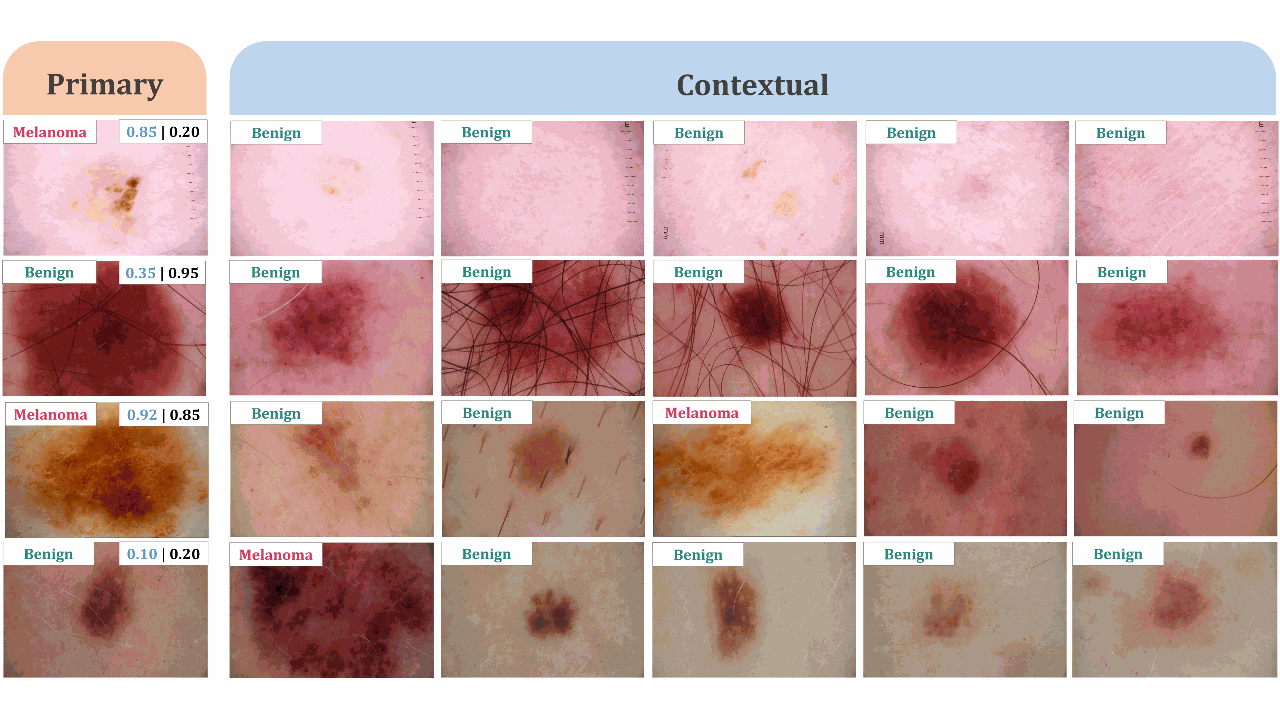 CIFF-Net: Contextual Image Feature Fusion for Melanoma DiagnosisMd Awsafur Rahman, Bishmoy Paul, Tanvir Mahmud, and 1 more authorElsevier BSPC, 2023
CIFF-Net: Contextual Image Feature Fusion for Melanoma DiagnosisMd Awsafur Rahman, Bishmoy Paul, Tanvir Mahmud, and 1 more authorElsevier BSPC, 2023Melanoma is considered to be the deadliest variant of skin cancer causing around 75% of total skin cancer deaths. To diagnose Melanoma, clinicians assess and compare multiple skin lesions of the same patient concurrently to gather contextual information regarding the patterns, and abnormality of the skin. So far this concurrent multi-image comparative method has not been explored by existing deep learning-based schemes. In this paper, based on contextual image feature fusion (CIFF), a deep neural network (CIFF-Net) is proposed, which integrates patient-level contextual information into the traditional approaches for improved Melanoma diagnosis by concurrent multi-image comparative method. The proposed multi-kernel self attention (MKSA) module offers better generalization of the extracted features by introducing multi-kernel operations in the self attention mechanisms. To utilize both self attention and contextual feature-wise attention, an attention guided module named contextual feature fusion (CFF) is proposed that integrates extracted features from different contextual images into a single feature vector. Finally, in comparative contextual feature fusion (CCFF) module, primary and contextual features are compared concurrently to generate comparative features. Significant improvement in performance has been achieved on the ISIC-2020 dataset over the traditional approaches that validate the effectiveness of the proposed contextual learning scheme.
@article{rahman2023ciff, title = {CIFF-Net: Contextual Image Feature Fusion for Melanoma Diagnosis}, author = {Rahman, Md Awsafur and Paul, Bishmoy and Mahmud, Tanvir and Fattah, Shaikh Anowarul}, journal = {Elsevier BSPC}, year = {2023}, doi = {10.1016/j.bspc.2023.105673}, url = {https://scholar.google.com/citations?view_op=view_citation&hl=en&user=zrxJCYIAAAAJ&citation_for_view=zrxJCYIAAAAJ:zYLM7Y9cAGgC}, }



2022
-
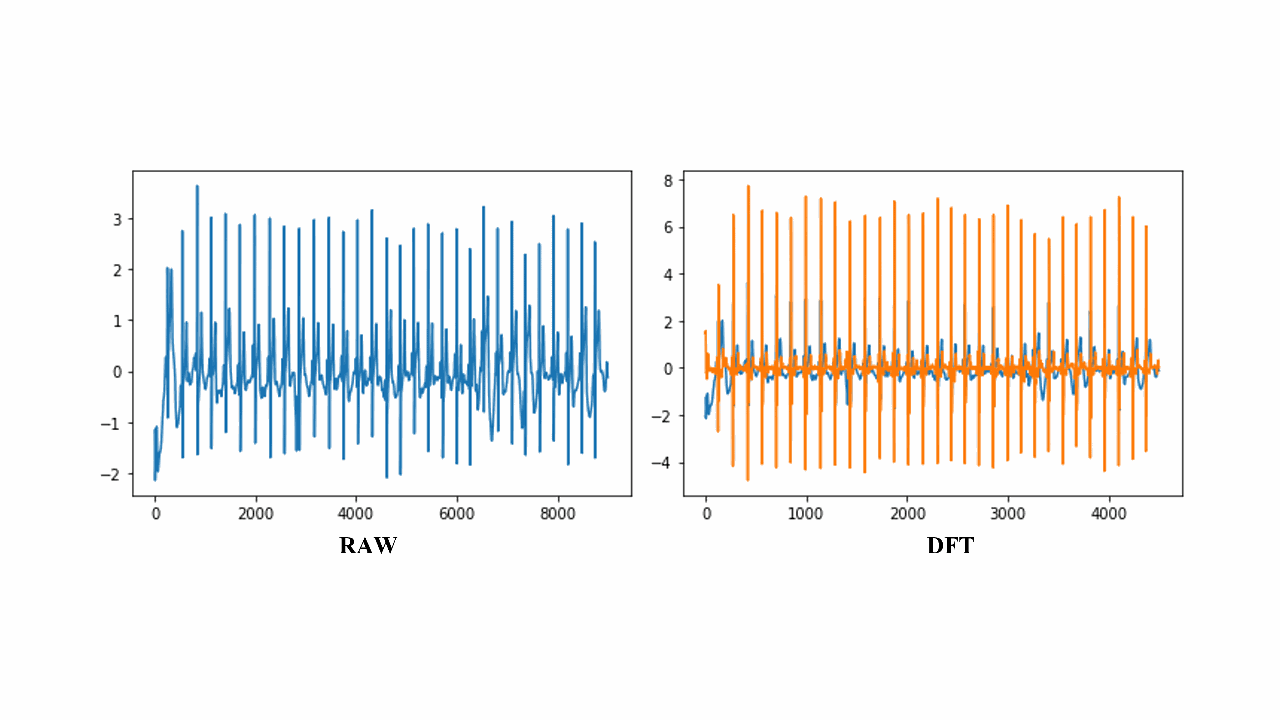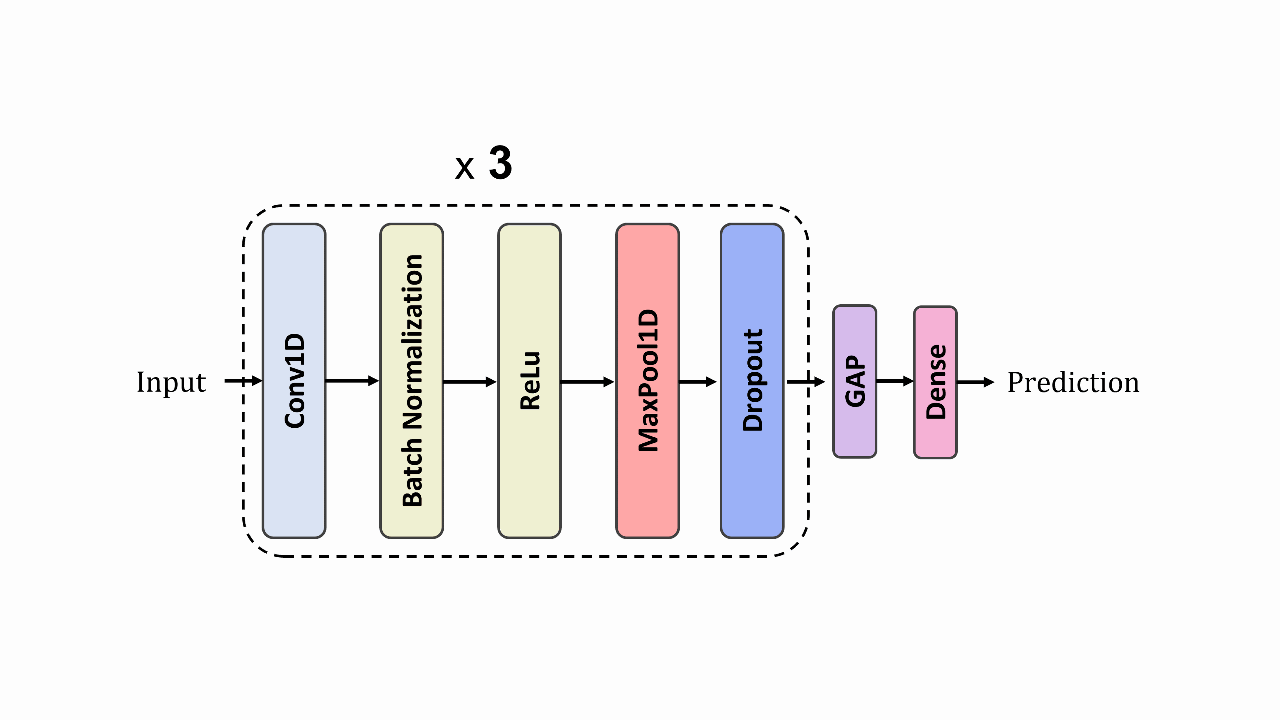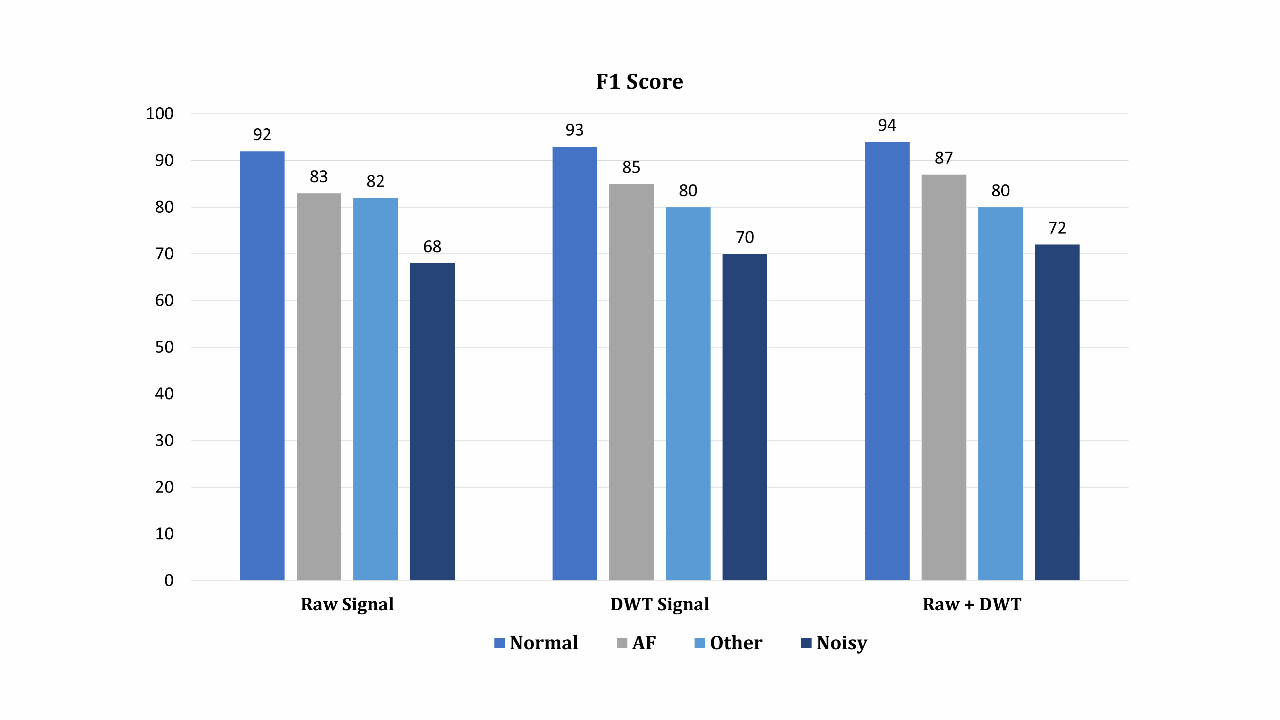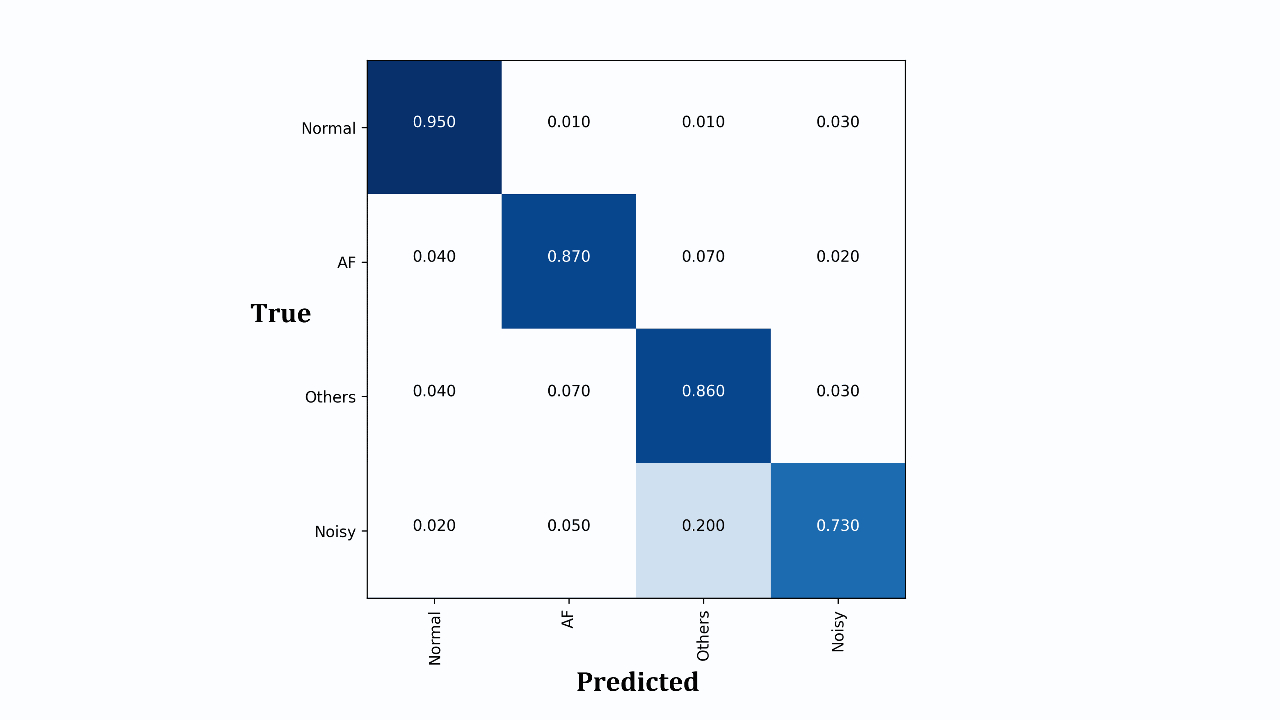 A Deep Learning Scheme for Detecting Atrial Fibrillation Based on Fusion of Raw and Discrete Wavelet Transformed ECG FeaturesMd Awsafur Rahman, Shahed Ahmed, and Shaikh Anowarul FattahIn EMBC, 2022
A Deep Learning Scheme for Detecting Atrial Fibrillation Based on Fusion of Raw and Discrete Wavelet Transformed ECG FeaturesMd Awsafur Rahman, Shahed Ahmed, and Shaikh Anowarul FattahIn EMBC, 2022Atrial fibrillation is the most common sustained cardiac arrhythmia and the electrocardiogram (ECG) is a powerful non-invasive tool for its clinical diagnosis. Automatic AF detection remains a very challenging task due to the high inter-patient variability of ECGs. In this paper, an automatic AF detection scheme is proposed based on a deep learning network that utilizes both raw ECG signal and its discrete wavelet transform (DWT) version. In order to utilize the time-frequency characteristics of the ECG signal, first level DWT is applied and both high and low frequency components are then utilized in the 1D CNN network in parallel. If only the transformed data are utilized in the network, original variations in the data may not be explored, which also contains useful information to identify the abnormalities. A multi-phase training scheme is proposed which facilitates parallel optimization for efficient gradient propagation. In the proposed network, features are directly extracted from raw ECG and DWT coefficients, followed by 2 fully connected layers to process features furthermore and to detect arrhythmia in the recordings. Classification performance of the proposed method is tested on PhysioNet-2017 dataset and it offers superior performance in detecting AF from normal, alternating and noisy cases in comparison to some state-of-the-art methods.
@inproceedings{rahman2022deep, title = {A Deep Learning Scheme for Detecting Atrial Fibrillation Based on Fusion of Raw and Discrete Wavelet Transformed ECG Features}, author = {Rahman, Md Awsafur and Ahmed, Shahed and Fattah, Shaikh Anowarul}, booktitle = {EMBC}, pages = {1024--1027}, year = {2022}, organization = {IEEE}, doi = {10.1109/EMBC48229.2022.9870829}, url = {https://scholar.google.com/citations?view_op=view_citation&hl=en&user=zrxJCYIAAAAJ&citation_for_view=zrxJCYIAAAAJ:d1gkVwhDpl0C}, }

2021
-
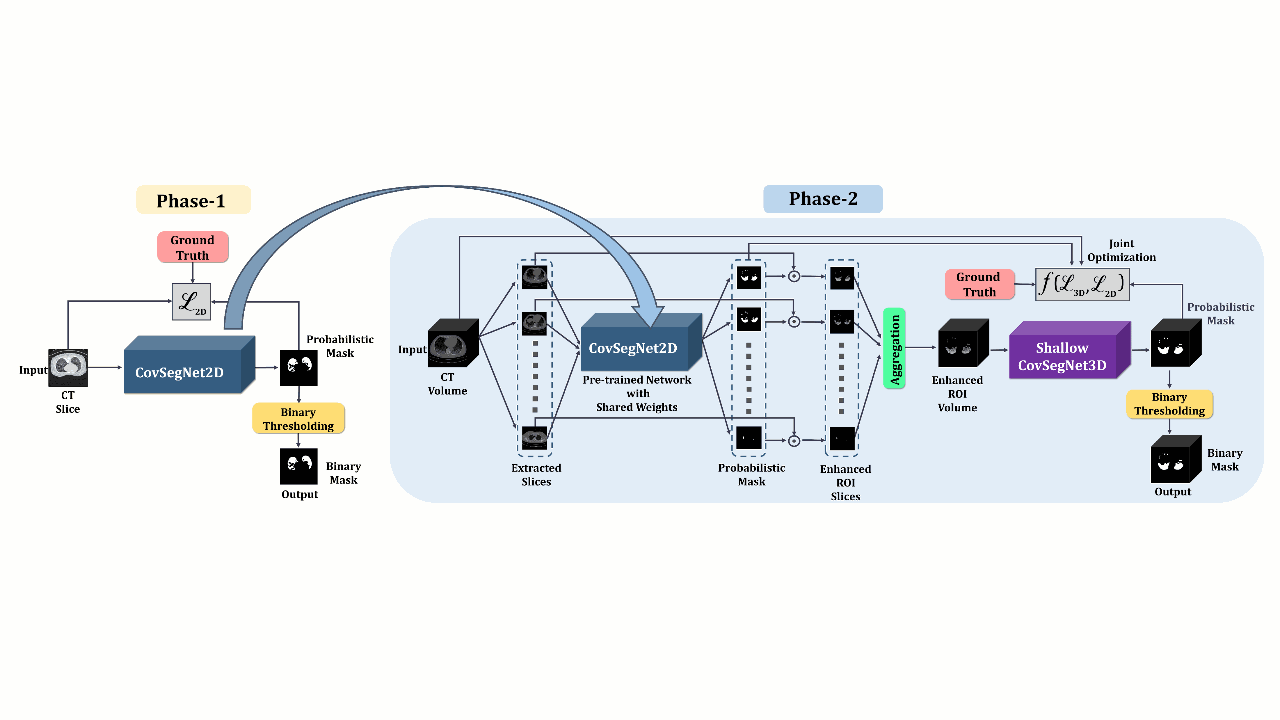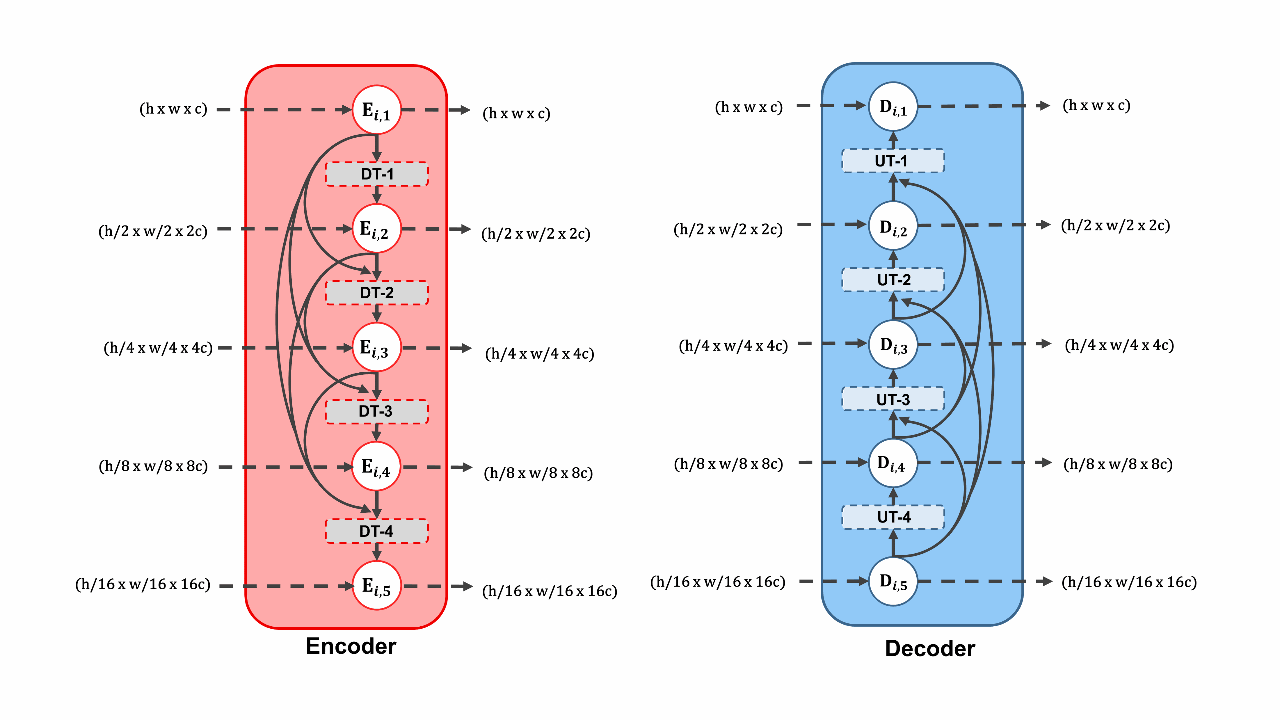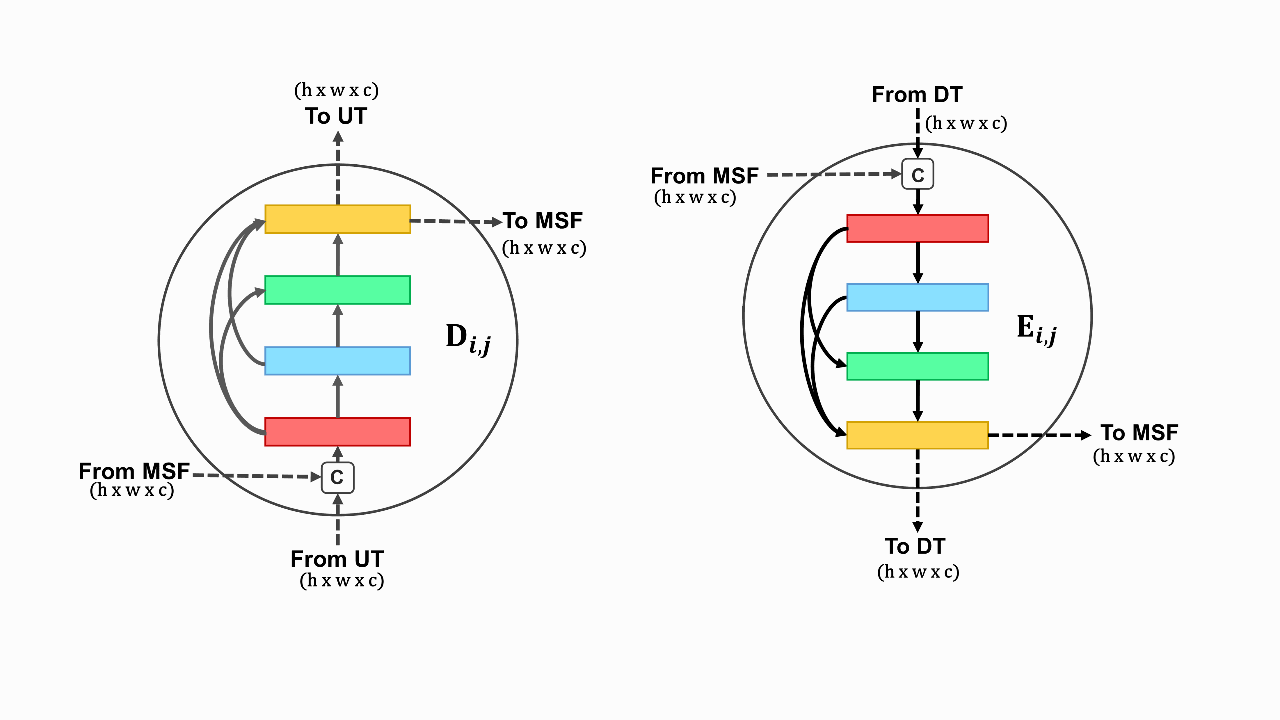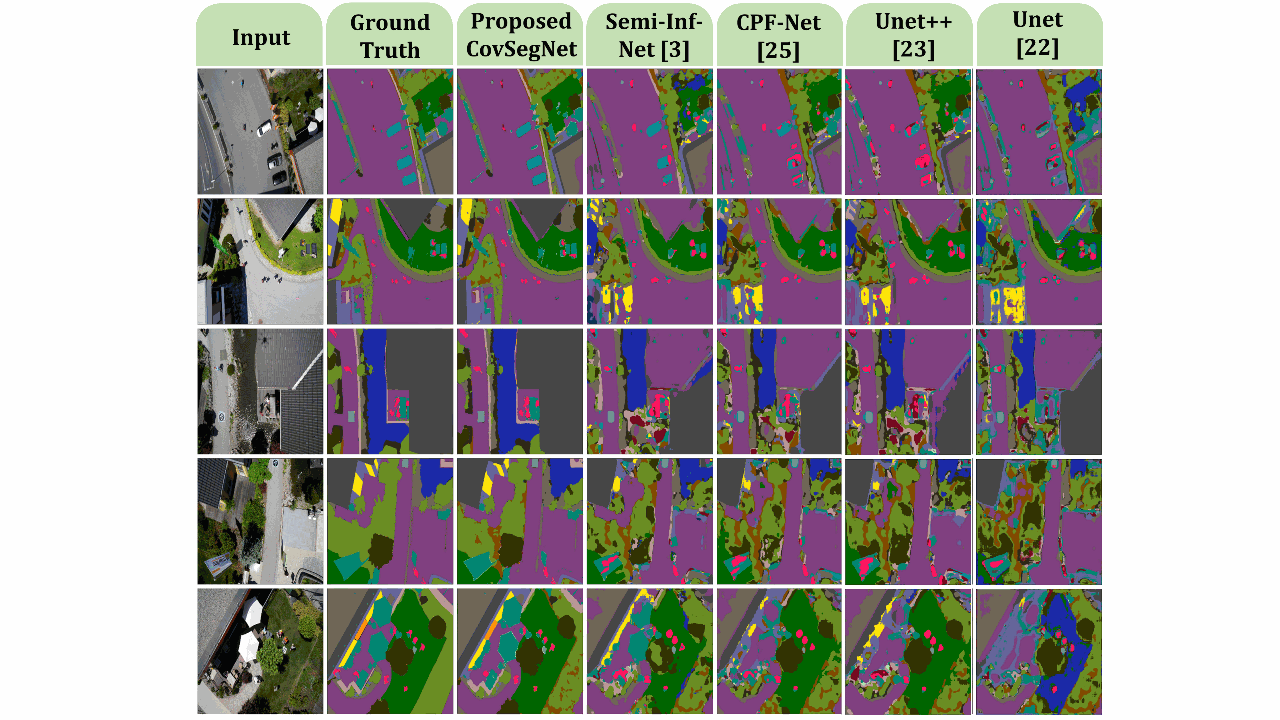 CovSegNet: A multi encoder–decoder architecture for improved lesion segmentation of COVID-19 chest CT scansTanvir Mahmud, Md Awsafur Rahman, Shaikh Anowarul Fattah, and 1 more authorIEEE Transactions on Artificial Intelligence, 2021
CovSegNet: A multi encoder–decoder architecture for improved lesion segmentation of COVID-19 chest CT scansTanvir Mahmud, Md Awsafur Rahman, Shaikh Anowarul Fattah, and 1 more authorIEEE Transactions on Artificial Intelligence, 2021Automatic lung lesion segmentation of chest computer tomography (CT) scans is considered a pivotal stage toward accurate diagnosis and severity measurement of COVID-19. Traditional U-shaped encoder-decoder architecture and its variants suffer from diminutions of contextual information in pooling/upsampling operations with increased semantic gaps among encoded and decoded feature maps as well as instigate vanishing gradient problems for its sequential gradient propagation that result in suboptimal performance. Moreover, operating with 3-D CT volume poses further limitations due to the exponential increase of computational complexity making the optimization difficult. In this article, an automated COVID-19 lesion segmentation scheme is proposed utilizing a highly efficient neural network architecture, namely CovSegNet, to overcome these limitations. Additionally, a two-phase training scheme is introduced where a deeper 2-D network is employed for generating region-of-interest (ROI)-enhanced CT volume followed by a shallower 3-D network for further enhancement with more contextual information without increasing computational burden. Along with the traditional vertical expansion of Unet, we have introduced horizontal expansion with multistage encoder-decoder modules for achieving optimum performance. Additionally, multiscale feature maps are integrated into the scale transition process to overcome the loss of contextual information. Moreover, a multiscale fusion module is introduced with a pyramid fusion scheme to reduce the semantic gaps between subsequent encoder/decoder modules while facilitating the parallel optimization for efficient gradient propagation. Outstanding performances have been achieved in three publicly available datasets that largely outperform other state-of-the-art approaches. The proposed scheme can be easily extended for achieving optimum segmentation performances in a wide variety of applications. Impact Statement-With lower sensitivity (60-70%), elongated testing time, and a dire shortage of testing kits, traditional RTPCR based COVID-19 diagnostic scheme heavily relies on postCT based manual inspection for further investigation. Hence, automating the process of infected lesions extraction from chestCT volumes will be major progress for faster accurate diagnosis of COVID-19. However, in challenging conditions with diffused, blurred, and varying shaped edges of COVID-19 lesions, conventional approaches fail to provide precise segmentation of lesions that can be deleterious for false estimation and loss of information. The proposed scheme incorporating an efficient neural network architecture (CovSegNet) overcomes the limitations of traditional approaches that provide significant improvement of performance (8.4% in averaged dice measurement scale) over two datasets. Therefore, this scheme can be an effective, economical tool for the physicians for faster infection analysis to greatly reduce the spread and massive death toll of this deadly virus through mass-screening.
@article{mahmud2021covsegnet, author = {Mahmud, Tanvir and Rahman, Md Awsafur and Fattah, Shaikh Anowarul and Kung, Sun-Yuan}, journal = {IEEE Transactions on Artificial Intelligence}, volume = {2}, number = {3}, pages = {283--297}, year = {2021}, publisher = {IEEE}, doi = {10.1109/TAI.2021.3064913}, url = {https://scholar.google.com/citations?view_op=view_citation&hl=en&user=zrxJCYIAAAAJ&citation_for_view=zrxJCYIAAAAJ:u5HHmVD_uO8C}, }

2020
-
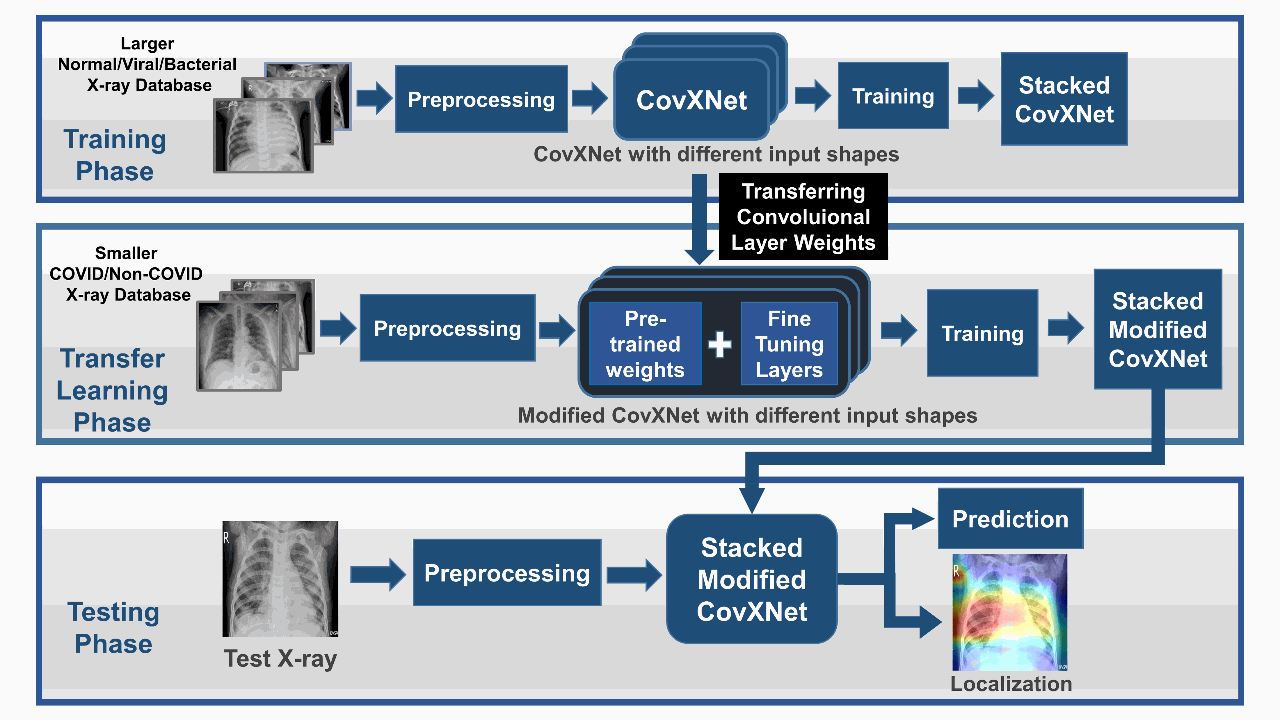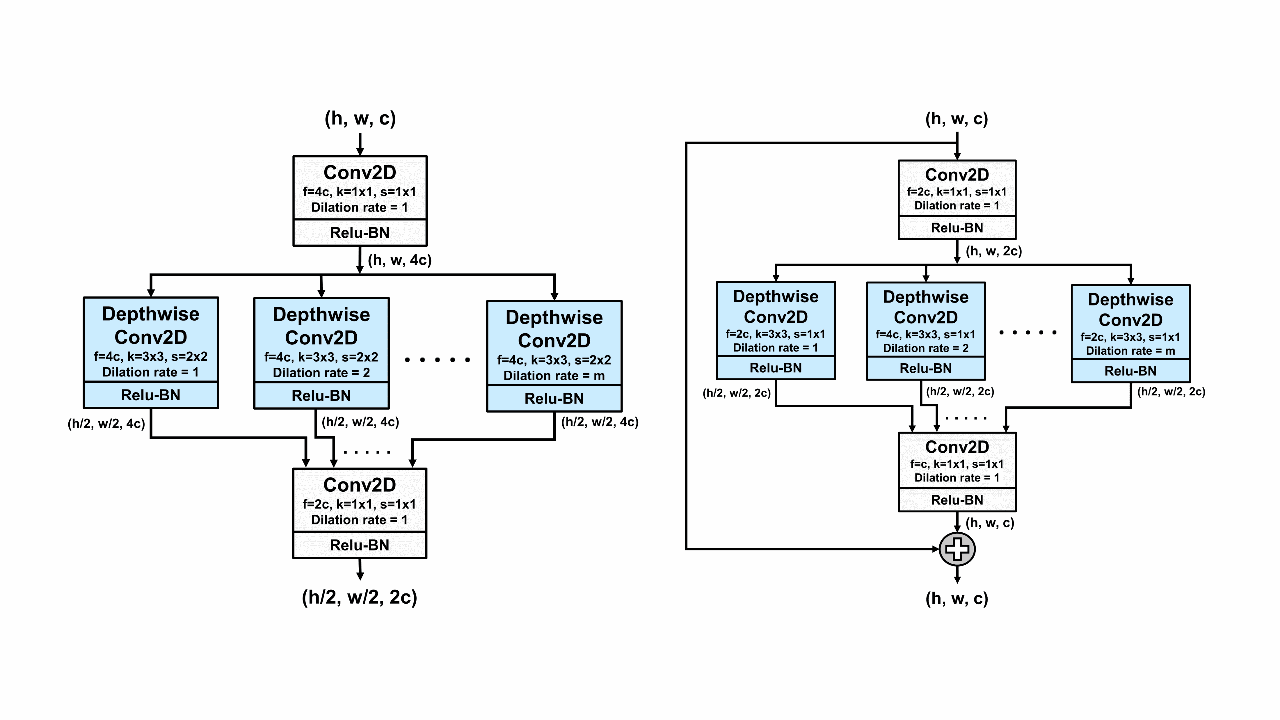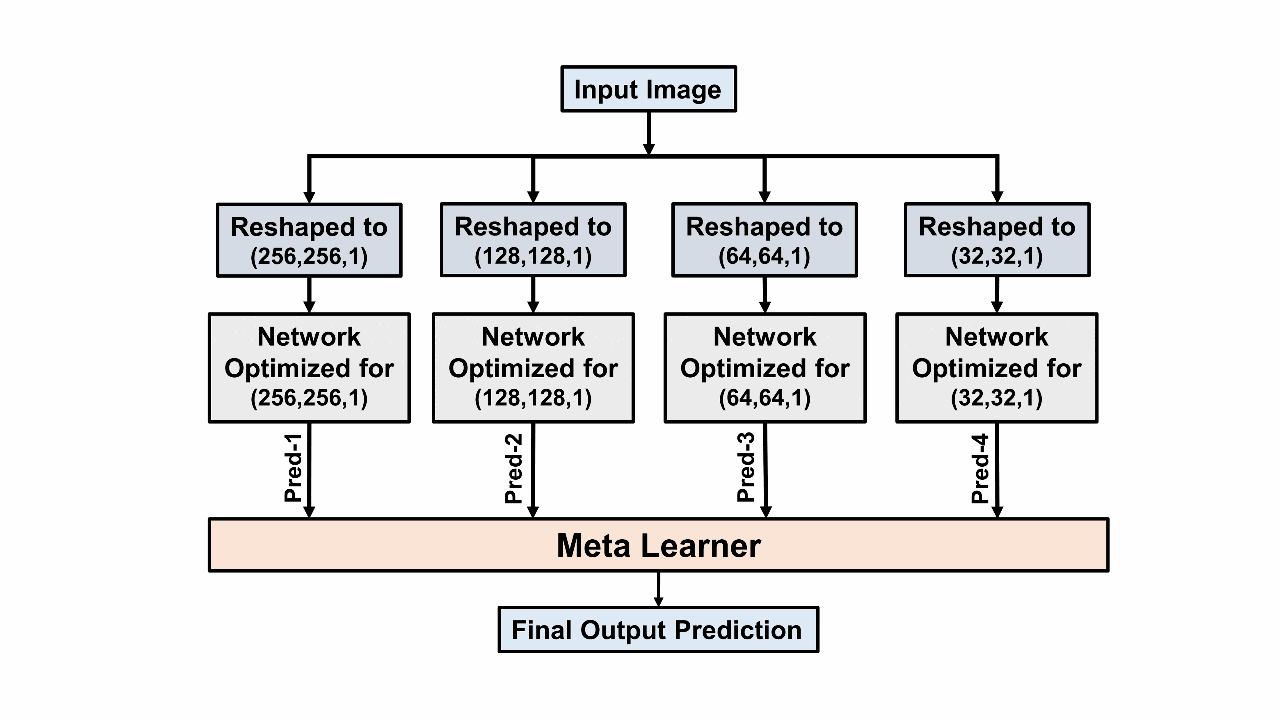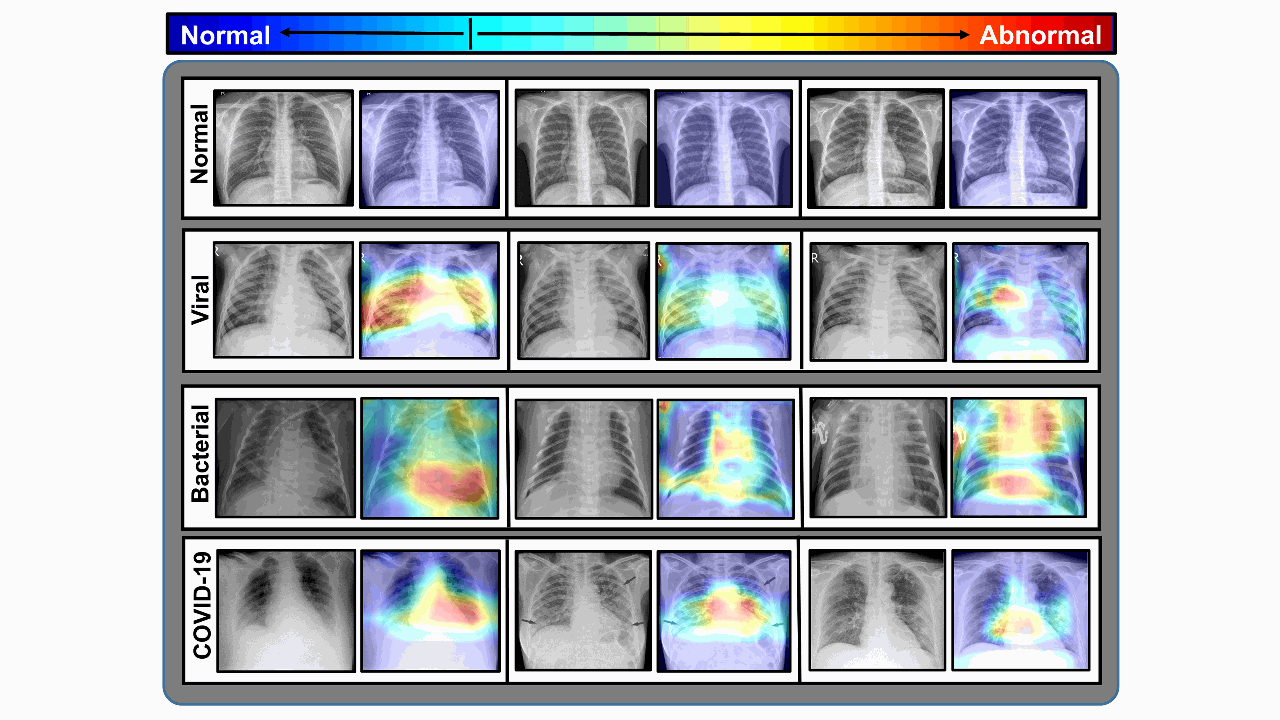 CovXNet: A multi-dilation convolutional neural network for automatic COVID-19 and other pneumonia detection from chest X-ray images with transferable multi-receptive feature optimizationTanvir Mahmud, Md Awsafur Rahman, and Shaikh Anowarul FattahComputers in biology and medicine, 2020
CovXNet: A multi-dilation convolutional neural network for automatic COVID-19 and other pneumonia detection from chest X-ray images with transferable multi-receptive feature optimizationTanvir Mahmud, Md Awsafur Rahman, and Shaikh Anowarul FattahComputers in biology and medicine, 2020With the recent outbreak of COVID-19, fast diagnostic testing has become one of the major challenges due to the critical shortage of test kit. Pneumonia, a major effect of COVID-19, needs to be urgently diagnosed along with its underlying reasons. In this paper, deep learning aided automated COVID-19 and other pneumonia detection schemes are proposed utilizing a small amount of COVID-19 chest X-rays. A deep convolutional neural network (CNN) based architecture, named as CovXNet, is proposed that utilizes depthwise convolution with varying dilation rates for efficiently extracting diversified features from chest X-rays. Since the chest X-ray images corresponding to COVID-19 caused pneumonia and other traditional pneumonias have significant similarities, at first, a large number of chest X-rays corresponding to normal and (viral/bacterial) pneumonia patients are used to train the proposed CovXNet. Learning of this initial training phase is transferred with some additional fine-tuning layers that are further trained with a smaller number of chest X-rays corresponding to COVID-19 and other pneumonia patients. In the proposed method, different forms of CovXNets are designed and trained with X-ray images of various resolutions and for further optimization of their predictions, a stacking algorithm is employed. Finally, a gradient-based discriminative localization is integrated to distinguish the abnormal regions of X-ray images referring to different types of pneumonia. Extensive experimentations using two different datasets provide very satisfactory detection performance with accuracy of 97.4% for COVID/Normal, 96.9% for COVID/Viral pneumonia, 94.7% for COVID/Bacterial pneumonia, and 90.2% for multiclass COVID/normal/Viral/Bacterial pneumonias. Hence, the proposed schemes can serve as an efficient tool in the current state of COVID-19 pandemic. All the architectures are made publicly available at: https://github.com/awsaf49/CovXNet
@article{mahmud2020covxnet, title = {CovXNet: A multi-dilation convolutional neural network for automatic COVID-19 and other pneumonia detection from chest X-ray images with transferable multi-receptive feature optimization}, author = {Mahmud, Tanvir and Rahman, Md Awsafur and Fattah, Shaikh Anowarul}, journal = {Computers in biology and medicine}, volume = {122}, pages = {103869}, year = {2020}, publisher = {Elsevier}, doi = {10.1016/j.compbiomed.2020.103869}, url = {https://scholar.google.com/citations?view_op=view_citation&hl=en&user=zrxJCYIAAAAJ&citation_for_view=zrxJCYIAAAAJ:u5HHmVD_uO8C}, }
